What is Machine Learning?
Get ready to crack interviews of top MNCs with Placement-ready courses Learn More!
Nowadays, many would agree that there’s no life without technology. Right from our basic needs to our entertainment, technology takes care of everything for us. The most astonishing boon of this technology undoubtedly has to be Machine Learning.
You would agree that right from Netflix suggesting you shows on the basis of your previous watch history to Facebook updating you about your friends’ activity on the basis of the pictures you post, ML has opened multiple doors of convenience for us. Don’t you think that it’d be fascinating to learn these technologies and get to know them better?
Today PythonGeeks will take you through the introductory part of the Machine Learning journey. In this article, we will discuss what is Machine Learning? Here, we will go through the history of Machine Learning while getting to know about its basics and other details. We will even look at some of the algorithms that we classify under Machine Learning. So, without further ado, let us quickly dive into the introductory part of the article.
What is Machine Learning?
In the technological world, we are all surrounded by humans who are able to learn everything from their experiences with their learning capability, and then we encounter computers or machines which work on our instructions. However, can a machine also learn from experiences or past data like we humans do? For the answer to this question, here comes the role of Machine Learning.
Machine Learning acts as a subset of artificial intelligence that mainly focuses on the development of algorithms that enables a computer to learn from the data and past experiences on their own. Arthur Samuel in 1959, first coined the term machine learning.
Machine learning allows a machine to automatically learn from data, enhance its performance from experiences, and thus predict things without being explicitly programmed or requiring any human intervention.
With the assistance of sample historical data, which we refer to as training data, machine learning algorithms tend to build a mathematical model that assists them in making predictions or decisions without being explicitly programmed. Machine learning fetches computer science and statistics together for the creation of predictive models. Machine learning fabricates or makes use of the algorithms that learn from historical data. The more we will offer the information, the higher will be the performance for any model.
Need for Machine Learning
We will now discuss some of the points that will prove the importance and need for Machine Learning in the smoothing working of today’s technological advancement.
1. Increase in Data Generation: Owing to excessive production of data, we require a method that we can use to structure, analyze as well as draw useful insights from data. This is the area where Machine Learning comes in for our rescue. It makes use of the data to solve problems and tends to look for solutions to the most complex tasks that organizations face.
2. Improve Decision Making: By using various algorithms, many organizations can make use of Machine Learning to make better business decisions. As an example, we make use of Machine Learning for forecasting sales, predicting downfalls in the stock market, identifying risks and anomalies, and many more such examples.
3. Uncover patterns & trends in data: Recognizing hidden patterns and extracting primary insights from data is the most crucial part of Machine Learning.
Through building predictive models and making use of statistical techniques, Machine Learning enables you to dig beneath the surface and explore the data at a minuscule scale. Analyzing data and extracting patterns manually will take quite some time, whereas Machine Learning algorithms are able to perform such computations in comparatively lesser time.
4. Solve complex problems: From the detection of the genes linked to the deadly ALS disease to building self-driving cars, we can make use of Machine Learning to solve the most complex problems.
Basic Terminologies Related to Machine Learning
Now that we know what actually we mean by Machine Learning, let us look at some of the basic terminologies that will help us to understand the further article in a better way.
1. Algorithm: A Machine Learning algorithm is a set of instructions and statistical techniques that we may use to learn patterns from data and draw insightful information from it. It is the primary logic behind the working of a Machine Learning model. An example of a Machine Learning algorithm is the KNN algorithm.
2. Model: A model is the preliminary component of Machine Learning. We tend to train a model by using a Machine Learning Algorithm. An algorithm tends to map all the possible decisions that a model is supposed to take on the basis of the given input, in an attempt to get the correct output.
3. Predictor Variable: It represents a feature of the data that we can use to predict the output.
4. Response Variable: It represents the feature or the output variable that we need to predict by using the predictor variable.
5. Training Data: We tend to build the Machine Learning model using the training data. The training data assists the model in the identification of the key trends and patterns essential to predict the output.
6. Testing Data: After we have successfully trained the model, we must test it in an attempt to evaluate how accurately it can predict an outcome. We can achieve this by the testing data set.
Working of Machine Learning
A Machine Learning system tends to learn from historical data, build the prediction models, and whenever we feed it with new data, predict the output for this new data. The accuracy of predicted output varies with the amount of data, as the huge amount of data assists us to build a better model which predicts the output more accurately.
For a better understanding, consider that we have a complex problem, in which we need to perform some predictions, so an alternative of writing a code for it, we just need to feed in the input data to generic algorithms, and with the assistance of these algorithms, machine fabricates the logic as per the data and tends to predict the output. Machine learning has changed our way of thinking about the problem in a better and more efficient way.
The below block diagram will accurately depict the working of the Machine Learning algorithm:
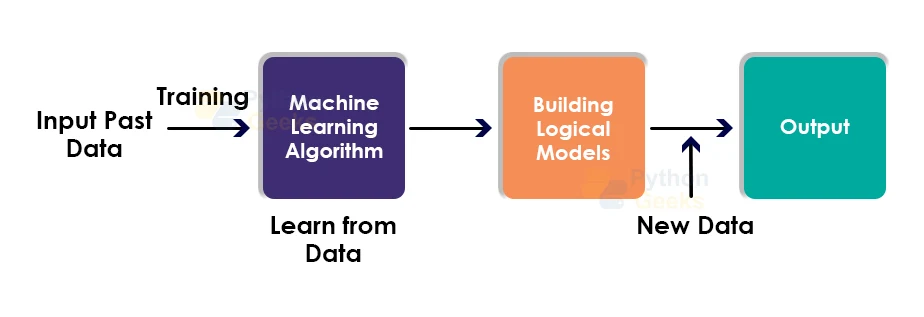
Features of Machine Learning
1. Machine learning makes use of data to recognize various patterns present in a given dataset.
2. It is capable of learning from past data and improving simultaneously.
3. It is a data-driven technology and helps us to predict the output better if we have enormous amounts of data.
4. Machine learning is comparatively similar to data mining since it even tends to deal with a huge amount of data.
Human Bias in Machine Learning
Although data and computational analysis may make us think that we are receiving objective information, this is not the case; being based on data does not mean that machine learning outputs are neutral. Human bias plays a role in how data is collected, organized, and ultimately in the algorithms that determine how machine learning will interact with that data.
If, for example, people are providing images for “fish” as data to train an algorithm, and these people overwhelmingly select images of goldfish, a computer may not classify a shark as a fish. This would create a bias against sharks as fish, and sharks would not be counted as fish.
Types of Machine Learning
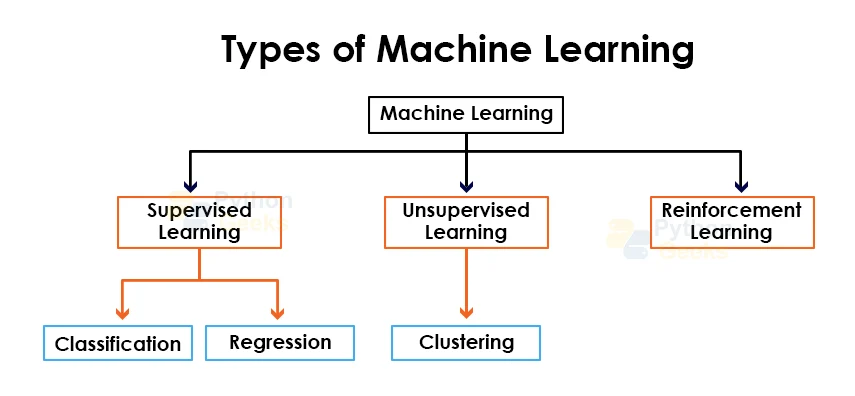
We can further bifurcate the Machine Learning algorithms into three types:
1. Supervised Learning
Supervised learning is a type of machine learning method in which we facilitate sample labeled data to the machine learning system in an attempt to train it, and on the basis of this training, it predicts the output.
The system fabricates a model using labeled data to analyze the datasets and learn about each data, once we are thorough with the training and processing then we tend to test the model by facilitating a sample data to check whether it has accurate and reliable prediction as to the exact output or not.
We can further divide Supervised Learning into two types.
a. Classification: When the output variable can be categorized as one of the kinds provided earlier, then such a problem comes under the category of Classification. For example, if we can categorize the output data as True-False pairs or other classes that exist for the problem. Some of the algorithms that come under this category are: Random Forest, Decision Tree, Logistic Regression, Support Vector Machine
b. Regression: These algorithms are used when you can relate the output with the input values provided. In other words, if we can predict the output on the basis of the previous inputs then the problem comes under the Regression Category.
Examples of such problems are Weather Forecasting, Market Trends, etc. Algorithms that come under this category are: Linear Regression, Regression Tree, Non-Linear Regression, Bayesian Linear Regression, Polynomial Regression
2. Unsupervised Learning
Unsupervised learning is a type of learning method in which a machine learns without the requirement of any supervision.
The training that we provide to the machine with the set of data that is not labeled, classified, or categorized, and the algorithm demands to act on that data without any supervision. Unsupervised learning aims to restructure the input data into new features or a group of objects with strikingly similar patterns.
We can further bifurcate Unsupervised Learning into two types.
a. Clustering: It is a method that groups objects with similar attributes into one category. In such a way, the objects whose attributes don’t match much with each other are placed in different groups. Cluster analysis tends to look for commonalities in the data objects and groups them on the basis of these commonalities.
b. Association: In association rule, the trained models tend to find relationships between the variables in an extensive dataset. It establishes a set of items that occurs together in the large dataset. In simple words, Association tends to study the behavior and the similarity between the data variables. Like an object X (e.g., bread) tends to be associated with the object Y (e.g., jam).
3. Reinforcement Learning
Reinforcement learning is a type of feedback-based machine learning method, in which a learning agent receives a reward for each accurate action and the algorithm penalizes the agent for each wrong action. The agent tends to learn automatically on its own with the help of this feedback and tries to improve its performance.
In reinforcement learning, the agent tends to interact with the environment and tends to explore it efficiently. The agent aims to get maximized reward points, and as a result of which, it enhances its performance.
Algorithms in Machine Learning
1. Bayesian Network
A Bayesian Network is an acyclic directed graphical model. This model is also called DAG which represents the probability of several independent conditioned variables.
One can illustrate the relationship between disease and symptoms. It can be used to compute the probabilities of various diseases. They can be used to find the diagnosis of several diseases through a calculated approach of listing probabilities of various factors that could have contributed to it.
2. Support Vector Machine
Support Vector Machines or SVMs are machine learning algorithms that are used to classify data into two categories or classes. It is a type of supervised learning algorithm that makes use of several types of kernels to classify the data. Based on the prediction performed, it can categorize whether it falls into one class or any other class.
3. Sparse Dictionary Learning
In the method of Sparse Dictionary, a linear combination of basis functions as well as sparse coefficients is assumed. The elements of a sparse dictionary are called atoms. These atoms altogether compose a dictionary. It is an extension of representation learning. It is used most widely in compressed sensing and signal recovery.
How to Choose the Right Machine Learning Solution?
We need to go through the following factors that will help us select the right kind of machine learning solution on the basis of supervised, unsupervised, and reinforcement learning:
1. Consider the situation in which you’d like to predict the future stock market prices. If you are a newbie to machine learning, you would have a hard time figuring out the right solution. However, with time and effective practice, you will start to understand that for a problem statement like this, solution-based supervised learning will yield the best results for obvious reasons.
2. Factors like the size, quality, and nature of the data are also quintessential factors. If we encounter clustered data, then we will tend to choose unsupervised. If our concerned data set is extensive and categorical, we ought to choose supervised learning solutions.
3. Finally, we should preferably choose a solution on the basis of the complexity of the algorithm. As for the problem statement where we need to predict stock market prices, using reinforcement learning can be a considerable solution, although that would be quite troublesome since it will be difficult and time-consuming, unlike supervised learning.
Approaches of Machine Learning
As a field, machine learning closely relates itself to computational statistics, so having a background knowledge in statistics proves to be beneficial for understanding and leveraging machine learning algorithms.
For those who may not have in-depth knowledge of statistics, it can be helpful to first try to define correlation and regression, as they are widely used techniques for investigating the relationship among quantitative variables.
Correlation tends to be a measure of association between two variables that do not have a designation of either dependent or independent. We make use of Regression at a basic level to examine the relationship between one dependent and one independent variable.
Some of the popular Machine Learning Approaches are:
1. K Nearest Neighbors: The k-nearest neighbor algorithm is a pattern recognition model that can be used for classification as well as regression. Often abbreviated as k-NN, the k in the k-nearest neighbor is a positive integer, which is typically small. In either classification or regression, the input will consist of the k closest training examples within a space.
2. Decision Tree Learning: For general use, decision trees are employed to visually represent decisions and show or inform decision-making. When working with machine learning and data mining, decision trees are used as a predictive model. These models map observations about data to conclusions about the data’s target value. The goal of decision tree learning is to create a model that will predict the value of a target based on input variables.
3. Deep Learning: Deep learning attempts to imitate how the human brain can process light and sound stimuli into vision and hearing. A deep learning architecture is inspired by biological neural networks and consists of multiple layers in an artificial neural network made up of hardware and GPUs.
History of Machine Learning
It was in the 1940s when the first manually managed computer system, ENIAC or the acronym for the original term, Electronic Numerical Integrator and Computer, was invented. At those times, people used the word “computer” as a name for a human having intensive numerical computation capabilities. As a result of this, ENIAC was called a numerical computing machine in that era.
You may say it has nothing to do with the learning factor of the machine?! This is where you are going wrong, since, from the beginning, the idea behind this was to build a machine that was able to emulate human thinking and learning processes.
In the 1950s, we can trace the roots of the first computer game program claiming to be capable of beating the checkers’ world champion. This program helped checkers players tremendously in improving their skills!
Around the same period, Frank Rosenblatt invented the Perceptron which was a striking classifier but when it was combined in enormous numbers, in a network, it became a much more powerful monster.
Well, the monster became relative to the time and in those times, it was a real breakthrough in the tech world. Then we witnessed several years of stagnation of the neural network field owing to its difficulties in solving certain problems.
However, because of statistics, machine learning became astonishingly famous in the 1990s. The juncture point of computer science and statistics gave birth to probabilistic approaches that are now present in AI.
Programming Languages for Machine Learning
When choosing a language to specialize in with machine learning, you may want to consider the skills listed on current job advertisements as well as libraries available in various languages that can be used for machine learning processes.
1. Python
Python’s popularity may be due to the increased development of deep learning frameworks available for this language recently, including TensorFlow, PyTorch, and Keras. As a language that has readable syntax and the ability to be used as a scripting language, Python proves to be powerful and straightforward both for preprocessing data and working with data directly.
2. Java
Java is widely used in enterprise programming and is generally used by front-end desktop application developers who are also working on machine learning at the enterprise level. Usually, it is not the first choice for those new to programming who want to learn about machine learning but is favored by those with a background in Java development to apply to machine learning.
In terms of machine learning applications in industry, Java tends to be used more than Python for network security, including in cyber-attack and fraud detection use cases.
3. C++
C++ is the language of choice for machine learning and artificial intelligence in-game or robot applications (including robot locomotion). Embedded computing hardware developers and electronics engineers are more likely to favor C++ or C in machine learning applications due to their proficiency and level of control in the language.
4. R
R is an open-source programming language used primarily for statistical computing. It has grown in popularity over recent years and is favored by many in academia. R is not typically used in industrial production environments but has risen in industrial applications due to increased interest in data science.
Applications of Machine Learning
Let us quickly look at some of the examples of the various wonders that are present in technology because of the advancement in Machine Learning.
1. Prediction — We can even use Machine learning in prediction systems. Considering the loan example for reference, in an attempt to compute the probability of a fault, the system will need to classify the available data into groups using the Machine Learning algorithms.
2. Image recognition — We can also make use of Machine learning for face detection in an image as well. There accounts for a separate category for each person in a database of several people of a certain group.
3. Speech Recognition — It indicates the translation of spoken words into the text. We can make use of it in voice searches and more. Voice user interfaces comprise voice dialing, call routing, and appliance control. We can even use it as a simple data entry and for the preparation of structured documents.
4. Medical diagnoses — We can effectively train ML to recognize cancerous tissues.
5. The financial industry and trading — Companies make use of ML in fraud investigations and credit checks.
6. In demand for companies — Google is one of the leading tech giants and it has made huge progress in AI and ML. Microsoft has one of the leading AL and ML programs in the world. Nvidia is one of the largest and most successful GPU makers in the world. It uses ML and data science to improve GPU processing quality to give better performance.
Intel is one of the leading chip and processor-making companies in the world. Its main goal is to make faster and more efficient processors so that your systems give better performance.
7. Popular Case Studies — Tesla is now a big player in the electric automobile industry. It is widely known for its advanced and futuristic cars. The company says that the cars have their own AI hardware.
Tesla is using AI for making self-driving cars. At the moment, cars are not completely autonomous. The company is working on a thinking algorithm for cars. It is currently working with NVIDIA on an unsupervised ML algorithm. This step by Tesla would be a game-changer for many reasons. The cars send data directly to Tesla’s cloud.
AI vs ML vs DL
Machine Learning
Machine learning may be a method of knowledge analysis that automates analytical model building. It’s a branch of AI that supports the thought that systems can learn from data, identify patterns and make decisions with minimal human intervention.
Machine Learning is a part of Artificial Intelligence that involves implementing algorithms that are able to learn from the data or previous instances and are able to perform tasks without explicit instructions.
Deep Learning
Deep learning is a component of a broader family of machine learning methods supporting artificial neural networks with representation learning. Learning is often supervised, semi-supervised or unsupervised.
Deep Learning is a part of Machine Learning that involves the usage of artificial neural networks. Deep Learning machine learning algorithms are the most popular choice in many industries due to the ability of neural networks to learn from large data more accurately and provide steadfast results to the user.
Artificial Intelligence
AI is the greater pool that contains an amalgamation of all the above-discussed technologies. Artificial Intelligence is still under research and involves imparting sentient intelligence to machines. However, Artificial General Intelligence is still far-fetched and will require years of research before we can have even a basic version of it.
Conclusion
With that, we have reached the end of this article that talked about what is Machine Learning? We came across the types and applications of Machine Learning. By getting to know all this, we can certainly conclude that Machine Learning will still continue to reign the arena of the Technological world and conquer greater heights with further advancements.
