Types of Machine Learning
Upgrade Your Skills, Upgrade Your Career - Learn more
Till now, we are convinced that Machine Learning is the present as well as the future of the tech world. We have come across various articles that talked about the applications and other basic concepts of Machine Learning. As we know, Machine learning is a vast field of study that overlaps with and inherits ideas from many related fields such as artificial intelligence, deep learning, and data science. In order to know this field a little better, we have to look at the classification of this vast technology.
As such, there are many different types of learning that you may encounter as a programmer, researcher, or general enthusiast of Machine Learning. PythonGeeks brings to you, an article that will guide you through the various classifications of Machine Learning in a rather comprehensive and easy-to-understand way. We will discuss the types of learnings, their applications, and the basis of their classification. Furthermore, we will also cover the pros and cons of these types of Machine Learning. So, without any delay, let us discuss the types of Machine Learning algorithms.
Types of Machine Learning
As we have learned earlier, the focus of the field of machine learning is “learning the way a human brain learns”, there are many types of Machine Learning that you may encounter as a general Machine Learning enthusiast.
Some types of learning describe whole subfields of study composed of many different types of algorithms in themselves such as “supervised learning.”
There are mainly 4 types of learning that you must be familiar with as a machine learning practitioner, namely:
Learning Problems
1. Supervised Learning
2. Unsupervised Learning
3. Reinforcement Learning
Hybrid Learning Problems
4. Semi-Supervised Learning
Now that we broadly know the types of Machine Learning Algorithms, let us try and understand them better one after the other.
1. Supervised Machine Learning
As you must have understood from the name, Supervised machine learning is based on supervision of the learning process of the machines. It indicates that in the supervised learning technique, we train the machines using the labeled or trained dataset, and on the basis of this training, the machine predicts the output. In this context, the labeled data specifies that some of the inputs that we feed to the algorithm are already mapped to the output.
To put it simply, in this type of Machine Learning, we try to teach the machines using the trained data and then expect it to predict the outcomes on the test data.
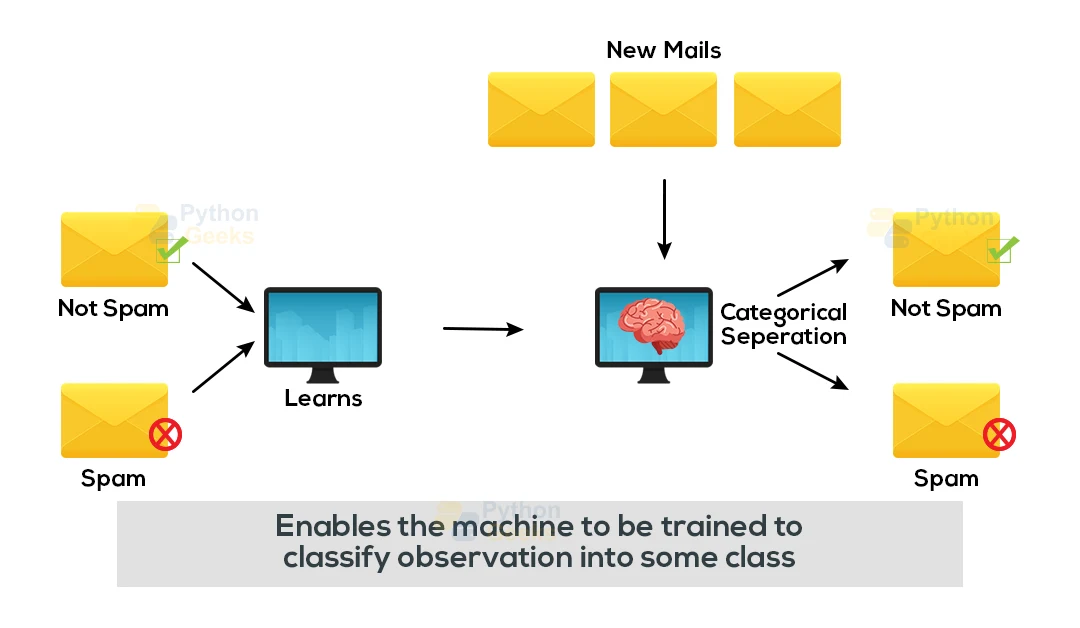
Let’s understand the working of supervised learning with an example. Consider that we have an input dataset of cats and dog images. As the first step, we will provide training to the machine to understand the images. It means that we will try to teach the machine to classify the images on the features such as the shape & size of the tail of cat and dog, Shape of eyes, color, height, and so on.
After successful completion of training, we input the picture of a cat and ask the machine to identify the object and predict the output on the basis of its training. As a result, the machine is well trained, so it will check all the classifying features of the object, such as height, shape, color, eyes, ears, tail, and ascertain that it’s a cat. So, it will classify the image in the Cat category.
Through this process, the machine identifies the objects in Supervised Learning.
Categories of Supervised Machine Learning
On the basis of the problem that we have to encounter, we can classify Supervised Learning into two categories:
a. Classification:
We use Classification algorithms to solve the classification problems in which the output variable is categorical. These categories can be of many types such as Yes or No, Male or Female, Red or Blue, and so on. The classification algorithms predict the categories present in the dataset on the basis of training data.
Some popular classification algorithms in practice are Random Forest, Algorithm, Decision Tree Algorithm, Logistic Regression Algorithm, Support Vector Machine Algorithm.
Some of the widely used Classification algorithms are:
- Random Forest Algorithm
- Decision Tree Algorithm
- Logistic Regression Algorithm
- Support Vector Machine Algorithm
b. Regression:
We use Regression algorithms to solve regression problems in which there exists a linear relationship between input and output variables. We can use these variables to predict continuous output variables, such as market trends, weather prediction, and so on.
Some of the popular Regression algorithms are: Simple Linear Regression Algorithm, Multivariate Regression Algorithm, Decision Tree Algorithm, Lasso Regression
Advantages of Supervised Learning
- Since supervised learning works with the labeled dataset, we can have an exact idea about the classification of objects and other variables that we feed in as input.
- These algorithms are helpful in predicting the output on the basis of prior experience and trained data.
Disadvantages of Supervised Learning
- These algorithms are not able to solve complex tasks due to a lack of data.
- It may predict the wrong output if the test data is different from the training data or the training data has some noise.
- It requires lots of computational time to train the algorithm and a huge load of trained data.
Applications of Supervised Learning
a. Image Segmentation:
We make use of Supervised Learning algorithms in image segmentation. In this process, we perform image classification on different image data with predefined labels in the dataset.
b. Medical Diagnosis:
We can also observe the usage of Supervised algorithms in the medical field for diagnosis purposes. It is achieved by using medical images and past labeled data with labels for disease conditions to accurately predict the aliments. With such a process, the machine can identify a disease for the new patients with the help of previous data history of other patients.
c. Fraud Detection:
We use Supervised Learning classification algorithms for identifying fraud transactions, fraud customers, and other financial frauds. We achieve this by using historic data to identify the patterns that can lead to possible frauds before they can occur.
d. Spam detection:
In the usage of spam detection & filtering, classification algorithms are quite effective and reliable. These algorithms are able to classify an email as spam or not spam. It then sends the spam emails to the spam folder.
e. Speech Recognition
Supervised learning algorithms are even used in speech recognition. We can even train the algorithm with voice data, and can even perform various identifications using the same, such as voice-activated passwords, voice commands, and so on.
2. Unsupervised Machine Learning
Unsupervised Machine Learning is far different from the Supervised learning technique in many ways. As you would have understood from the name, there is no need for supervision in this type of Machine Learning. It indicates that, in unsupervised machine learning, we train the machine using the unlabeled or untrained dataset, and the machine predicts the output without any supervision of such data.
In unsupervised learning, we train the models with the data that is neither classified nor labeled, and the model acts on that data without performing any supervision methods.
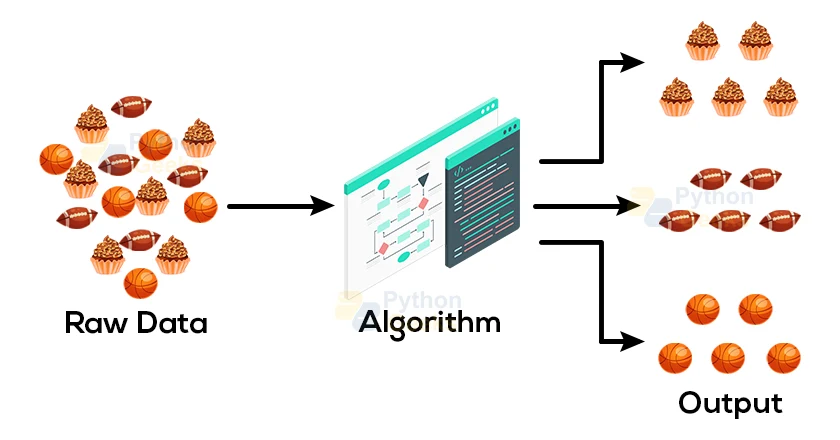
The main aim of the unsupervised learning algorithm is to group or categorize the unsorted dataset according to the similarities, patterns, and differences that it recognizes from the dataset. We instruct the Machines to recognize the hidden patterns from the input dataset and analyze the results.
Types of Unsupervised Learning
a. Clustering:
We make use of the clustering technique when we want to look for the inherent groups from the data. It is a technique to group the objects into a cluster. We group the objects such that the objects with the most similarities are classified in one group and have fewer or no similarities with the objects of other groups.
Some of the popular clustering algorithms are given below: K-Means Clustering algorithm, Mean-shift algorithm, DBSCAN Algorithm, Principal Component Analysis, Independent Component Analysis
b. Association
Association rule learning is a type of unsupervised learning technique, which looks for interesting relations among variables within a large dataset that we feed in as input. This algorithm aims to find the dependency of one data item on another data item and map those variables accordingly so that it can generate maximum profit from the unsorted large dataset.
Some of the popular algorithms of Association rule learning are Apriori Algorithm, Eclat, FP-growth algorithm.
Advantages of Unsupervised Learning
- We can use these algorithms for complicated tasks as compared to the supervised ones because these algorithms work on unlabeled datasets and do not require large datasets.
- Unsupervised algorithms are preferable for various tasks as getting the unlabeled dataset is easier as compared to the labeled dataset for the training of these algorithms.
Disadvantages of Unsupervised Learning
- An unsupervised algorithm may result in less accurate outputs as the dataset is not labeled, and we have not trained the algorithms with the exact output beforehand.
- Working with Unsupervised learning is more difficult as compared to other types as it works with the unlabelled dataset that does not map with the output precisely.
Applications of Unsupervised Learning
a. Network Analysis:
We use Unsupervised learning for identifying plagiarism and copyright in document network analysis of text data for scholarly articles and prevent copyright frauds.
b. Recommendation Systems:
Recommendation systems extensively makes use of unsupervised learning techniques for building recommendation applications for different web applications and e-commerce websites for convenience and popularity of products.
c. Anomaly Detection:
Anomaly detection is a widely used application of unsupervised learning, which can identify unusual data points within a large input dataset. We extensively use it to discover fraudulent transactions.
d. Singular Value Decomposition:
We use Singular Value Decomposition or commonly known as SVD to extract a certain type of information from the database. For example, extraction of information of each user located at a certain geographical location.
3. Semi-Supervised Learning
Semi-Supervised learning is yet another type of Machine Learning algorithm that lies between or is a hybrid of Supervised and Unsupervised machine learning. It demonstrates the intermediate ground between Supervised and Unsupervised learning algorithms and makes use of the combination of labeled and unlabeled data sets during the training period for the machines.
Although Semi-supervised learning is the middle ground between supervised and unsupervised learning and we use it on the data that consists of a few label datasets, it mostly comprises unlabeled data. As these labeled datasets are quite expensive, but for corporate purposes, they may require a few labeled datasets. It is completely different from supervised and unsupervised learning since they are based on the presence and absence of labeled data.
In order to overcome the drawbacks of supervised learning and unsupervised learning algorithms, we came up with the concept of Semi-supervised learning. Semi-supervised learning aims to effectively use all the available data, rather than only labeled data like in supervised learning. Initially, the model clusters together similar data along with an unsupervised learning algorithm. Furthermore, it helps to put labels on the unlabeled data and turns it into labeled data. We perform this step because labeled data is quite expensive as compared to untrained data.
Advantages of semi-supervised learning
- It is quite simple and easy to understand the algorithm and does not encounter anomalies.
- This is highly efficient in predicting the output on the basis of input data.
- It overcomes the drawbacks of Supervised and Unsupervised Learning algorithms.
Disadvantages of semi-supervised learning
- Iteration results may not be stable and outputs may vary significantly.
- We cannot apply these algorithms to network-level data due to its complexities.
- The accuracy rate for this type of Learning is low.
4. Reinforcement Learning
Reinforcement learning operates on a feedback-based process, in which an Artificial Intelligence agent automatically explores its surroundings by hit and trial methods. It takes action, learns from experiences, and improves its performance. The algorithm rewards such agents for each good action and punishes it for each bad action. Hence, the reinforcement learning agent aims to maximize the rewards and minimize the punishments.
In reinforcement learning, the algorithm does not require any labeled data like supervised learning, and agents solely learn from their experiences.
The reinforcement learning process is similar to the learning process of a human being. As an example, consider a child that learns various things by his day-to-day life experiences. A simple example to understand reinforcement learning is to play a game, where the Game mimics the environment, moves of an agent at each step define states of the game, and the goal of the agent is to get a high score at the end of the game. Agent receives feedback in terms of punishments and rewards that it collects at the end.
Classification of Reinforcement Learning
1. Positive Reinforcement Learning
Positive reinforcement learning specifies increasing the tendency that the required behavior would occur again and again by adding something. It enhances the strength of the behavior of the agent and positively leaves an impact.
2. Negative Reinforcement Learning:
Negative reinforcement learning works exactly in the opposite way as compared to positive Reinforcement Learning. It tends to increase the tendency that the specific behavior would occur again by avoiding the negative condition that will lead to punishment.
Use cases of Reinforcement Learning
a. Video Games:
Reinforcement Learning algorithms are extensively used in gaming applications. It is used to acquire superhuman performance in theme-based gaming. Some popular games that make use of this type of algorithm are AlphaGO and AlphaGO Zero.
b. Resource Management:
The “Resource Management with Deep Reinforcement Learning” paper demonstrates how to use this type of learning in computers to automatically learn and helps them in resource scheduling which helps the resources to wait for different jobs in order to minimize average job slowdown.
c. Robotics:
This type of learning is extensively being used in Robotics applications. We make use of Robots in the industrial and manufacturing area, and we can make these robots more powerful with reinforcement learning. There are different industries that have a keen eye for building intelligent robots using AI and Machine learning technology.
d. Text Mining:
Text mining, to date, is one of the greatest applications of NLP. We now tend to implement NLP with the help of Reinforcement Learning by Salesforce company.
Advantages of Reinforcement Learning
- This type of learning assists us in solving complex real-world problems which are difficult to be solved by general techniques that we use conventionally.
- The learning model of Reinforcement Learning is similar to the learning process of human beings; therefore, we can look for the most accurate results.
- This type of learning helps us in achieving long-term results.
Disadvantages of Reinforcement Learning
- We generally do not prefer these algorithms for simple problems.
- These algorithms require huge data and high computational powers.
- Too much reinforcement learning can lead to an overload of states which can weaken the results defying the purpose of deploying them.
Other Learning Methods
Some types of learning describe whole subfields of the study that comprise many different types of algorithms such as “supervised learning.” Others describe powerful techniques that we can use on our projects, such as “transfer learning.” We will try to understand these techniques in brief.
a. Hybrid Learning Problems
The lines between unsupervised and supervised learning are quite blurry, and there are many hybrid approaches that draw from each field of study and are quite popular as well. Semi-Supervised Learning is one such type.
Apart from Semi-Supervised Learning, there are two more types of Hybrid Learning that are known to date. They are:
- Self-Supervised Learning: Self-supervised learning represents an unsupervised learning problem that is framed as a supervised learning problem in an attempt to apply supervised learning algorithms to tackle it.
- Multi-Instance Learning: It is a supervised learning problem where individual examples exist as unlabeled; whereas, bags or groups of samples are labeled.
b. Statistical Inference
Inference refers to reaching out to an outcome or decision. In machine learning, fitting a model and making an accurate prediction are both types of inference. There are different paradigms for the inference that we may use as a framework for understanding how some machine learning algorithms work or how we may approach some learning problems.
Some of the Statistical Inference Learning Techniques are:
- Inductive Learning: It involves using evidence to determine the outcome. Inductive reasoning refers to using specific cases to determine general outcomes, for example, specific to general.
- Deductive Learning: Deductive inference indicates the usage of general rules to determine specific outcomes. We can understand induction by contrasting it with deduction. The deduction is the inverse action of induction. If induction is moving from the specific to the general, the deduction is moving from the general to the specific.
- Transductive Learning: It is used in the field of statistical learning theory to indicate to predicting specific examples given specific examples from a domain. It is comparatively different from induction that involves learning general rules from specific examples.
Machine Learning Techniques
There are many techniques that we may describe as types of learning. Types of these learnings are:
a. Multi-Task Learning:
It is a type of supervised learning that involves fitting a model on one dataset that addresses multiple similar problems. It makes the involvement of devising a model that we can train on multiple related tasks in such a way that it enhances the performance of the model by training across the tasks as compared to being trained on any single task.
b. Active Learning:
It is a technique where the model is capable of handling queries of a human user operator during the learning process in order to resolve ambiguity during the learning process of the model.
c. Online Learning:
It involves using the data available and updating the model directly prior to a prediction is required or after the model makes the last observation. Online learning is an accurate solution for those problems where we provide observations over time and where we expect the probability distribution of observations to also change over time. As a consequence of this, we then expect the model to change just as frequently in order to capture and harness those changes.
d. Transfer Learning:
It is a type of learning where we first train a model on one task, then we use some or all of the model as the starting point for a related task.
e. Ensemble Learning:
Ensemble learning is an approach where we tend to fit two or more modes on the same data and then combine the predictions from each model. The ensemble learning aims to achieve better performance with the ensemble of models as compared to any individual model. This includes the involvement of both deciding how to create models that we use in the ensemble and how to efficiently combine the predictions from the ensemble members.
Conclusion
With that, we have reached the end of the article that talked about the different types of Machine Learning algorithms. We came across their basic definition and the working of these algorithms in brief. Furthermore, we also covered the various applications as well as the advantages and disadvantages of these algorithms. Hope that this article from Pythongeeks was able to solve all your queries regarding Machine Learning and its types.
