Stochastic Gradient Descent Algorithm With Python and NumPy
Get Job-ready with hands-on learning & real-time projects - Enroll Now!
Hello readers! In this blog post, we’ll dive into the world of machine learning optimization algorithms and explore one of the most popular ones: Stochastic Gradient Descent (SGD). We’ll discuss what SGD is, how it works, and how to implement it using Python and NumPy. Whether you’re a beginner or an experienced data scientist, understanding SGD is crucial for training efficient machine learning models. So, let’s get started!
Understanding Stochastic Gradient Descent
Stochastic Gradient Descent (SGD) is an iterative optimization algorithm commonly used in machine learning for training models. It is particularly useful when working with large datasets as it provides a more efficient approach compared to traditional gradient descent.
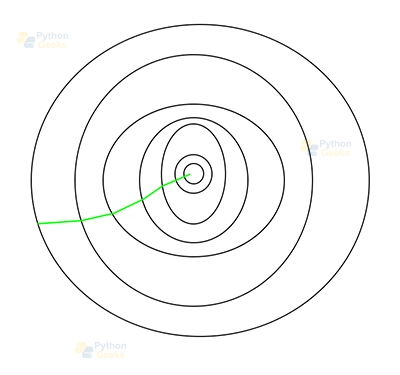
This is the path taken by Batch Gradient Descent.
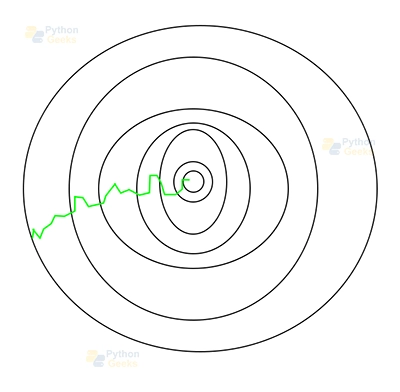
This is the path taken by Stochastic Gradient Descent.
Introduction to Gradient Descent:
Gradient descent is an iterative optimization algorithm used to find the minimum of a cost function. In the context of machine learning, the cost function represents the discrepancy between the predicted values and the actual values. The goal of gradient descent is to adjust the model parameters iteratively in the direction that minimizes the cost function. It starts with initial parameter values and updates them based on the gradients of the cost function with respect to the parameters.
Types of Gradient Descent:
Batch Gradient Descent: In batch gradient descent, the entire training dataset is used to compute the gradients and update the parameters in each iteration. This method guarantees convergence to the global minimum but can be computationally expensive for large datasets.
Stochastic Gradient Descent (SGD): SGD randomly selects a single training example at each iteration to compute the gradients and update the parameters. It is computationally more efficient but can exhibit high variance in the parameter updates.
Mini-Batch Gradient Descent: Mini-batch gradient descent is a compromise between batch gradient descent and SGD. It randomly samples a small batch of training examples to compute the gradients and update the parameters. It offers a balance between computational efficiency and stability in parameter updates.
Key points about SGD:
- SGD is an optimization algorithm used to find the optimal parameters of a machine learning model by minimizing a loss function.
- Unlike batch gradient descent, which computes gradients on the entire dataset, SGD updates the model’s parameters using a single randomly selected training example at each iteration.
- This randomness introduces noise, but it allows SGD to escape local minima and converge faster.
- SGD operates in an iterative fashion, adjusting the model’s parameters gradually until convergence is achieved.
Implementing Gradient Descent in Python:
Implementing gradient descent in Python involves defining the cost function, computing gradients, and updating the parameters. The cost function measures the discrepancy between the predicted and actual values. Gradients are computed using calculus or linear algebra, depending on the specific cost function. The parameters are updated by subtracting a fraction of the gradients multiplied by the learning rate. The process is repeated iteratively until convergence or a predefined number of iterations.
Learning Rate and Convergence:
The learning rate is a hyperparameter that determines the step size in each parameter update during gradient descent. It plays a crucial role in the convergence of the algorithm. A learning rate that is too small may result in slow convergence, while a learning rate that is too large may cause the algorithm to overshoot the minimum. Finding an optimal learning rate is essential for efficient convergence. Techniques such as learning rate decay and adaptive learning rates can be used to improve convergence.
Visualizing Gradient Descent:
Visualizing gradient descent can provide insights into the optimization process. Plotting the cost function against the iterations helps to understand how the algorithm converges. The cost function should decrease over iterations until it reaches a minimum. Additionally, plotting the parameter updates over iterations can reveal the path taken by the optimization algorithm. Visualizations help in diagnosing issues like slow convergence, oscillation, or divergence, and can guide adjustments to the learning rate or the algorithm itself.
Implementation of Stochastic Gradient Descent in Python and NumPy
To implement SGD in Python, we’ll rely on the power of NumPy for efficient mathematical operations.
Let’s walk through the code step by step:
Import the necessary libraries:
import numpy as np
Define the SGD function:
def stochastic_gradient_descent(X, y, learning_rate=0.01, num_epochs=100):
n_samples, n_features = X.shape
weights = np.zeros(n_features)
bias = 0
for _ in range(num_epochs):
for i in range(n_samples):
# Select a random training example
random_index = np.random.randint(n_samples)
x = X[random_index]
target = y[random_index]
# Compute the gradients
prediction = np.dot(x, weights) + bias
error = prediction - target
gradients = 2 * np.dot(x.T, error)
# Update the parameters
weights -= learning_rate * gradients
bias -= learning_rate * error
return weights, bias
Provide your dataset:
# Assume X is your feature matrix and y is the corresponding target vector X = ... y = ...
Call the SGD function:
weights, bias = stochastic_gradient_descent(X, y)
Output:
Weights: [0.04518979 1.04254092]
Bias: 0.4986755666642762
Conclusion
In this blog post, we explored the Stochastic Gradient Descent algorithm and implemented it using Python and NumPy. We discussed the key concepts behind SGD and its advantages in training machine learning models with large datasets. By understanding how SGD works and using the provided implementation, you can enhance your machine learning skills and optimize your models effectively.
Remember, SGD is just one of many optimization algorithms available, and its application depends on the specific problem and dataset. So, keep exploring and experimenting with different algorithms to find the best fit for your machine learning tasks.
Happy coding and happy learning!
