Regularization in Machine Learning
Get Job-ready with hands-on learning & real-time projects - Enroll Now!
Over the period of time, we came across various articles that discussed the merits, demerits, applications as well as numerous algorithms in the domain of Machine Learning. The striking feature of all these articles was that each article spoke about the importance of avoiding overfitting. You might have encountered overfitting in real senses when your Machine Learning proved exceptionally well on the training data.
However, it lagged a great deal when you tested it with unseen data sets. These situations degrade the overall performance of your model, leading to inaccuracy and decreased efficiency. In an attempt to avoid overfitting, data scientists make use of a technique called Regularization in machine learning.
In this PythonGeeks article, we will discuss this technique known as regularization. We will walk through the various aspects of regularization, its need, working, and type of regularization. We will try to observe the difference between the two types of regularization in brief. Towards the end, we will have a discussion over the achievement of regularization. So, without further delay, let’s dive straight into the article to know more about regularization.
Why Regularization?
We may encounter certain situations where our Machine learning model operates well on the training data but does not cross the mark when we use it on the unseen or test data. It indicates to the problem that the model is not able to serve its purpose of predicting the output or target column for the unseen data by introducing noise in the output. This makes the model highly inaccurate and we call such kinds of models “overfitted” models.
Let us try to understand what exactly we want to say with the term noise in the output. The term noise refers to those data points in the dataset which don’t really represent the true properties of our data but exist in the dataset only due to a random chance. To put it simply, noise is the redundant data points of the data set which do not contribute significantly to the dataset and just produce errors in the final output.
So, to overcome the problem of overfitting, in order words, to avoid the interference of noise, we take the help of regularization techniques while deploying any Machine Learning model.
What is Regularization?
Regularization is amongst one of the most crucial concepts of machine learning. To put it simply, it is a technique to prevent the machine learning model from overfitting by taking preventive measures like adding extra information to the dataset.
We have already seen that the overfitting problem occurs when the machine learning model performs well with the training data but it is not able to produce the expected output with the test data. It means the model is not able to accurately predict the output when it has to deal with unseen or test data by the introduction of noise in the output, and hence we call the model is overfitted. We can avoid this problem with the help of regularization techniques to get accurate results.
This technique mainly focuses on maintaining all the crucial variables or features in the model by reducing the magnitude of the variables to avoid noise. Hence, it is able to maintain accuracy along with a generalization of the model and avoid overfitting conditions.
The technique tends to regularize or reduce the coefficient of features towards a null value. To put it in a rather comprehensive way, we try to reduce the magnitude of the features by keeping the same number of features in the regularization technique in an attempt to avoid overfitting.
What is Regularization Parameter in Machine Learning?
For the datasets consisting of linear regression, regularization consists of two main parameters, namely, Ordinary Least Square (OLS) and the penalty term.
We can define the loss function of the regression in regularization by:
Loss function (regularization) = loss function (OLS) + penalty.
In the above equation, we can find penalty using:
Penalty = λ * w
Here, λ is the regularization parameter whereas w is the weight associated with the regularization.
The regularization parameter in machine learning is λ and has the following features:
- It tries to impose a higher penalty on the variable having higher values, and hence, it controls the strength of the penalty term of the linear regression.
- This is a tuning parameter that controls the bias-variance trade-off.
- λ can take values ranging from 0 to infinity
- If λ = 0, then it means there is no difference between a model with and without regularization and helps to find out if the model is overfitted or not.
How does Regularization work?
As we have seen in the above sections, Regularization tends to serve its purpose by adding a penalty or complexity term to the complex model in an attempt to avoid overfitting. Let us try to understand this by considering the simple linear regression equation:
y= β0+β1×1+β2×2+β3×3+⋯+βnxn +b
In the above-mentioned equation, Y represents the value that the model needs to predict as the output.
X1, X2, …Xn represents the features of the value Y.
β0, β1……βn represents the weights or magnitude associated with the features of the value Y, respectively. Here, b represents the intercept of the linear regression equation.
The main focus of the Linear regression models is to try to optimize the β0 and b in an attempt to minimize the cost function of the model. We can represent the equation for the cost function for the linear model with the help of the following equation:
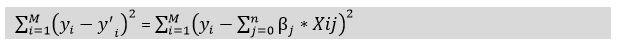
Furthermore, we will add a loss function and try to optimize parameters in an attempt to make a model that can predict the accurate value of Y. We can call the loss function for the linear regression as RSS or Residual sum of squares.
Regularization Techniques in Machine Learning
We can further divide regularization into parts, namely, Lasso Regression and Ridge Regression
1. Lasso Regression
Lasso regression is a type of regularization technique that aims to reduce the complexity of the overfitted model. It is the acronym for Least Absolute and Selection Operator. It works in a similar fashion as compared to the Ridge Regression except for the fact that the penalty term in Lasso regression contains only the absolute weights instead of considering a square of weights.
Due to the fact that it takes absolute values, it is able to shrink the slope to 0, whereas Ridge Regression can only shrink it to a near to 0 value. It is also known by the term L1 regularization. We can represent the equation for the cost function of Lasso regression by:

We majorly neglect some of the features associated with this technique for model evaluation. Due to this reason, the Lasso regression can help us to reduce the overfitting in the model along with the feature selection benefit.
Limitations of Lasso Regression
a. Problematic to handle some types of Datasets: If the number of predictors for any given dataset is greater than the number of data points, the Lasso regression technique will pick at most n predictors as non-zero, even if all predictors are relevant, hence being inefficient in handling the predictors.
b. Multicollinearity Problem: If there exist two or more highly collinear variables in the dataset, then LASSO regression chooses one of them randomly which is not good for the interpretation of our model since we need to consider the most appropriate variables for the accuracy of the results.
2. Ridge Regression
Ridge regression is one of the types of linear regression in which we introduce a small amount of bias so that we can get better long-term predictions results for the model. It is a type of regularization technique, which we use to reduce the complexity of the model in an attempt to avoid overfitting. We also know this regularization technique by the name of L2 regularization.
In this technique, we tend to alter the cost function by adding the penalty term to the cost function. The amount of bias that we add to the model is called the Ridge Regression penalty of that particular model. We can calculate Ridge Regression Penalty by multiplying it with the lambda to the squared weight of each individual feature present in the dataset. We can represent the equation for the cost function in ridge regression by:

In the above equation, the penalty term tends to regularize the coefficients of the model, which in turn helps the ridge regression to reduce the amplitudes of the coefficients that decrease the complexity of the overfitted model.
As we can see from the above equation, if the values of λ tend to be zero or try to become null, then the equation represents the cost function of the linear regression model. Hence, for the minimum value of λ, where it tends to be a null value, the model will tend to resemble the linear regression model.
As we already know, generally linear or polynomial regression is bound to fail if there is high collinearity between the independent variables of the dataset. In an attempt to solve such problems, we can make use of the Ridge regression. It helps us to solve the problems our dataset comprises more parameters than the samples present in the dataset.
Usage of Ridge Regression
a. When we encounter a dataset that has independent variables which are having high collinearity (problem of multicollinearity) between them, general linear or polynomial regression will fail to tackle such problems. We can make use of Ridge regression to make the model free of the overfitting conditions.
b. If we have more parameters associated with the data points than the samples present in the dataset, then Ridge regression helps the model to solve the problems of overfitting.
Limitations of Ridge Regression
a. Does not help in Feature Selection: Though ridge regression decreases the complexity of a model, it does not reduce the number of independent variables. This happens because it never leads to a coefficient being zero rather it only minimizes the coefficient of the variables. Hence, cannot make use of this technique as this technique is not good for feature selection.
b. Model Interpretability: The major disadvantage of this technique is model interpretability since it will shrink the coefficients for least important predictors, very close to zero but it will never make them exactly zero and hence it does not tend to nullify the overfitting conditions. In simple words, the final model will include all the independent variables, also known as predictors and thus the final output will also have noise to some extent.
Key differences between Ridge and Lasso Regularization
a. We mostly make use of Ridge regression to reduce the overfitting in the model. It includes all the features present in the overfitted model. It reduces the complexity of the model by shrinking the coefficients unlike, Lasso regression.
b. Lasso regression helps to reduce the overfitting in the model along with the benefit of feature selection.
What does Regularization in Machine Learning achieve?
As we have studied earlier, a standard least-squares model tends to have some variance present in it. It indicates that this model won’t be able to generalize well for a data set that is different from its training data.
Regularization significantly reduces the variance of the model by adding necessary variables, without a substantial increase in its bias. As a result of this, the tuning parameter λ, that we use in the regularization techniques described in the above equation, controls the impact on bias and variance of the given dataset.
As the value of λ rises, it reduces the value of coefficients. This results in the reduction of the variance. To a point, this increase in λ proves beneficial for the model as it is only reducing the variance resulting in avoidance of overfitting, without losing any important properties in the data. However, after attaining a certain value, the model starts losing important properties, giving rise to bias in the model and thus resulting in the creation of an overfitted model. Therefore, we need to carefully select the value of λ to properly serve its purpose.
Conclusion
With this, we have reached the end of this article that talked about the basics of regularization in machine learning. We came across the need for regularization as well as the working of the regularization techniques. We also came across the various regularization techniques, their limitations as well as their uses in machine learning. Hope that this article from PythonGeeks was able to solve all your queries regarding Regularization and its need.
