Python OpenCV Text Detection and Extraction – Decode the Secrets
Boost Your Career with In-demand Skills - Start Now!
Text detection and extraction are important tasks in computer vision and natural language processing. They are commonly used in many applications such as optical character recognition (OCR), document analysis, and text recognition in images and videos.
OpenCV is a popular open-source library for image and video processing, which offers various tools for text detection and recognition. By combining OpenCV with OCR engines, we can extract text from images and videos, which can be used for automated text recognition and translation.
In this project, we will go over the basics of text detection and extraction using OpenCV and OCR, and explain the key algorithms and techniques involved.
What is Text Detection ?
Text detection is the process of finding text in an image or video. The aim is to locate all the text in the image, regardless of the font size, style, or how it’s positioned in the image. This is an essential step in various applications such as scanning documents, recognizing text, and retrieving information from images.
What is Text Extraction ?
Text extraction is the process of turning the text in an image or document into a computer-readable format. The objective of text extraction is to accurately recognize and reproduce the text in a digital format that can be easily manipulated and analyzed by computer algorithms.
Text extraction is crucial in various applications, such as scanning and digitizing documents, analyzing texts, and processing natural language. Text extraction techniques typically use OCR software to scan the image or document and recognize the text patterns, which are then converted into a machine-readable text format.
How OpenCV and OCR are used to define a structural element ?
OpenCV is a tool that helps us with computer vision and machine learning tasks. OCR is a technology that can recognize text from images. To recognize text from an image, we need to identify the geometric shapes that represent the text in the image, such as rectangles, circles, or ellipses. OpenCV provides functions that can detect these shapes in an image.
Once we have identified the structural elements, OCR algorithms are used to recognize the text within them. OCR algorithms segment the image into smaller regions based on the structural elements detected, and then they process these segments to recognize the characters present in them.
Combining OpenCV and OCR, we can create powerful text recognition systems that accurately recognize text from images. We can use these systems in various applications such as document scanning, automatic number plate recognition, and digital image processing.
How OpenCV and OCR are used to “find contours in the dilated image”?
OpenCV and OCR can work together to find the boundaries of an object in an image, which is known as a contour. This is an essential step in many computer vision applications, including object detection and recognition.
To find the contour, we first pre-process the image to enhance the object’s edges using techniques like thresholding or edge detection. Then, we apply dilation, a morphological operation, to make the object’s boundaries more distinct. Using the findContours function in OpenCV, we can detect the object’s contours, which are represented as a sequence of points. Finally, OCR can be used to recognize and extract text from the image by analyzing the shapes and patterns of the text and matching them to a known character database.
Prerequisites for Text Detection and Extraction using Python OpenCV
It is important to have a solid understanding of the Python programming language and the OpenCV library in order to perform Text Detection and Extraction. Apart from this you should have the following system requirements.
1. Python 3.7 and above
2. Any python editor (VS code, Pycharm)
3. Tesseract Setup
Download Python OpenCV Text Detection and Extraction Project
Please download the source code of Python OpenCV Text Detection and Extraction Project from the following link: Python OpenCV Text Detection and Extraction Project Code
Tesseract Setup
To set up Tesseract OCR for text extraction using OpenCV, you can follow these steps:
1. Install Tesseract OCR: You can download and install Tesseract OCR from below link https://github.com/UB-Mannheim/tesseract/wiki
2. To install Pytesseract open cmd as administrator and type the following cmd.
pip install pytesseract
3. Set Path: After installing Tesseract copy the path of the folder where you install tesseract and add this in your system environment variable.
Installation
Open windows cmd as administrator
1. To install the opencv library run the command from the cmd.
pip install opencv-python
2. To install the Pillow library run the command from cmd.
pip install pillow
Let’s Implement it
To implement it follow the below step.
1. First of all we are importing all the necessary libraries that are required during implementation.
import cv2 from PIL import Image import pytesseract
2. This sets the path to the executable file of the Tesseract OCR engine on a Windows operating system.
The path to the Tesseract executable file is set to “C:/Program Files/Tesseract-OCR/tesseract.exe”, which is the default installation path for Tesseract OCR engine on Windows.
pytesseract.pytesseract.tesseract_cmd = r"C:/Program Files/Tesseract-OCR/tesseract.exe"
3. This will open the laptop’s camera and store the camera input in the camera variable.
camera = cv2.VideoCapture(0)
4. Start the while loop
while True:
5. This captures images or frames from a video camera in python using the opencv library. camera.read() function reads the next frame available from the camera and returns two values ret, image. Ret is boolean that returns whether the frame from the camera is successfully read or not. Captured image is stored in the second variable.
ret, image = camera.read()
6. If the frame from the camera is successfully not read then the loop will break to stop capturing images.
if not ret:
break
7. This reads an image from a video camera, converts it to grayscale, applies thresholding to make it binary, and then uses Tesseract OCR to recognize any text in the image. If text is detected, it is printed to the console and the original image with text detection results is displayed in a new window.
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, thresholded = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY +cv2.THRESH_OTSU)
text = pytesseract.image_to_string(Image.fromarray(thresholded), config='--psm 11')
text = text.strip()
if len(text) > 0:
print(text)
cv2.imshow('PythonGeeks', image)
8. This will allow you to stop the programme by pressing the key ‘q’.
if cv2.waitKey(1) & 0xFF == ord('q'):
break
Note :- step 5,6,7,8 you have to include this under the while loop.
9. After pressing the key ‘q’ all the windows will be closed
camera.release() cv2.destroyAllWindows()
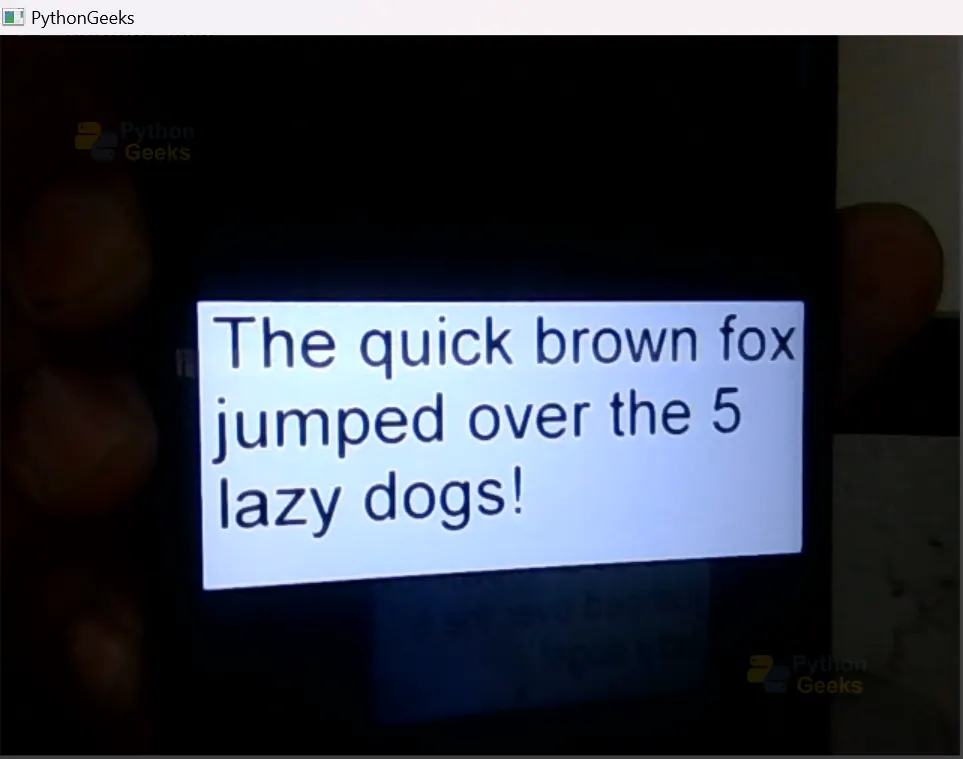
Output

Text Detection and Extraction from Image
To extract the text from the image follow the below steps.
1. Import all the libraries that are required for the implementation
import cv2 from PIL import Image import pytesserac
2. This sets the path to the executable file of the Tesseract OCR engine on a Windows operating system.
The path to the Tesseract executable file is set to “C:/Program Files/Tesseract-OCR/tesseract.exe”, which is the default installation path for Tesseract OCR engine on Windows.
pytesseract.pytesseract.tesseract_cmd = r"C:/Program Files/Tesseract-OCR/tesseract.exe"
3. Give the image path from where you want to extract the text.
image = cv2.imread('img.jpg')
4. This reads an image, converts it to grayscale, applies thresholding to make it binary, and then uses Tesseract OCR to recognize any text in the image. If text is detected, it is printed to the console and the original image with text detection results is displayed in a new window.
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, thresholded = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY +cv2.THRESH_OTSU)
text = pytesseract.image_to_string(Image.fromarray(thresholded), config='--psm 11')
text = text.strip()
print(text)
cv2.imshow('PythonGeeks', image)
5. cv2.waitKey(0) waits for a key press, and cv2.destroyAllWindows() closes all OpenCV windows.
cv2.waitKey(0) cv2.destroyAllWindows()
Text Detection and Extraction Output

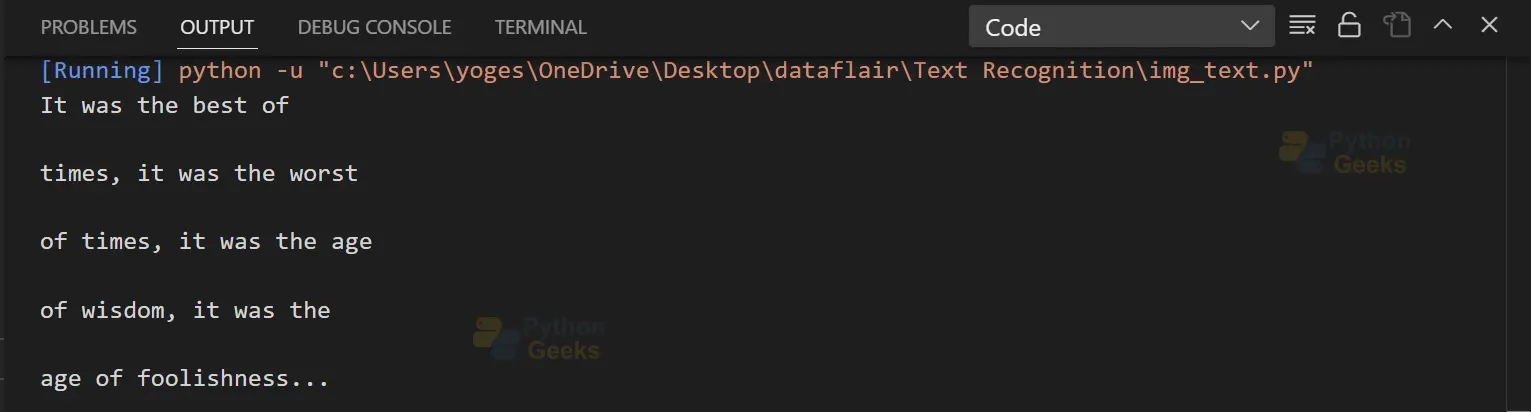
Conclusion
In this project, we showed how to use OpenCV and OCR to detect and extract text from images. We discussed techniques like binarization and thresholding to prepare the image for OCR. We also used the Tesseract OCR engine to extract text from the image.
This project is a good starting point for anyone interested in text detection and extraction using OpenCV and OCR, and can be used to build more advanced text recognition systems for various applications like document scanning and image-based search.
