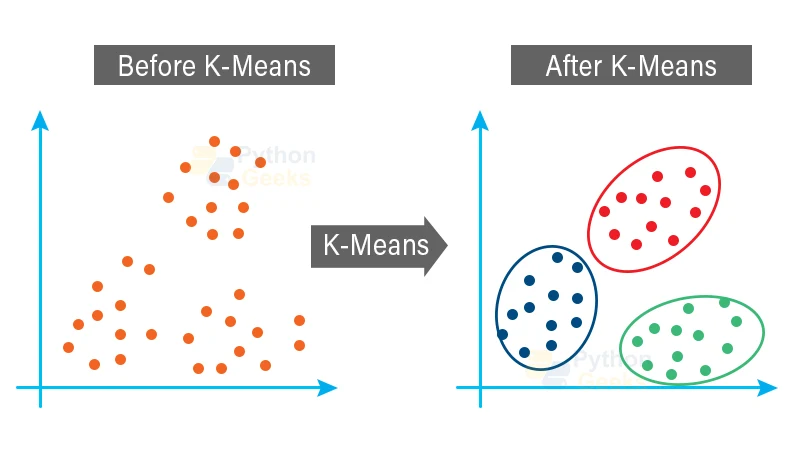
K-means Clustering in Machine Learning
Master Programming with Our Comprehensive Courses Enroll Now!
To date, K-Means Clustering enjoys the position of being one of the most popular Machine Learning algorithms. It is a type of unsupervised learning algorithm, indicating that we use it for unlabeled datasets. Consider that you have certain points spread over an n-dimensional space.
In an attempt to categorize this data on the basis of their similarity, we need to use the K-means clustering algorithm. In this article, PythonGeeks will take you through this algorithm in detail. Furthermore, we will discuss the basic Python libraries that we can use to implement this algorithm.
K-means clustering algorithm is an unsupervised technique to group data in the order of their similarities. We then find patterns within this data that are present as k-clusters.
What is K-means Clustering?
K-Means Clustering is a type of Unsupervised Learning algorithm that tends to group the unlabeled dataset into diverse clusters. K-means clustering algorithm is an unsupervised learning technique to group data on the basis of their similarities. We then try to find patterns within this data that exist as k-clusters.
In the given context, K indicates the number of predefined clusters that we need to create beforehand in the process. As a consideration, if K=3, there will be three clusters, and for K=12, there will be twelve clusters, and the pattern continues in a similar fashion.
This is an iterative algorithm that tends to divide the unlabeled dataset into k diverse clusters in such a way that each dataset strictly belongs to only one group that has similar properties to our concerned dataset.
It permits us to cluster the data into several groups and is a convenient way to discover the categories of groups in the unlabeled dataset on its own exclusive of the need for any training.
It tends to be a centroid-based algorithm, where the algorithm associates with a centroid. The algorithm mainly aims to minimize the sum of distances between the data point and their corresponding clusters within the dataset.
We feed in the algorithm with the unlabeled dataset as input, the algorithm then divides the dataset into k-number of clusters and tends to repeat the process until it does not find the appropriate clusters. The value of k should strictly be predetermined while using this algorithm.
The k-means clustering algorithm mainly tends to perform two tasks:
1. Tries to determine the best value for K center points or centroids by an iterative process.
2. Aims to assign each data point to its closest k-center. Those data points within the input dataset which are near to the particular k-center, create a cluster.
As a result of which, each cluster has data points with certain commonalities, and it stays away from other clusters.
Working of the K-means Algorithm
We can explain the working of the K-Means algorithm with the help of the below steps:
1. Pre-determine the number K to decide the number of clusters.
2. Choose random K points or centroids. (It can even be different from the input dataset).
3. Assign each data point to their corresponding closest centroid, which will form the predefined K clusters that we need for the algorithm.
4. Calculate the variance and position a new centroid of each cluster.
5. Iterate over the three steps, which indicates reassigning each datapoint to the new closest centroid of each cluster.
6. If we encounter any reassignment, then move back to step-4 else go to the end step.
7. The model is ready to use and is quite accurate and reliable.
Methods to choose the “k number of clusters” in k-means Clustering
We can determine the performance of the K-means clustering algorithm with the help of the highly efficient clusters that it forms. However, determining the optimal number of clusters is quite troublesome. There are certainly different ways to decide the optimal number of clusters. However, in this article, we will discuss the most appropriate and widely used method to find the number of clusters or value of K. The method that we commonly use for determining the number of clusters is:
1. Elbow Method
The Elbow method is one of the most widely-used ways to find the optimal number of clusters. This method makes use of the concept of WCSS value. WCSS is the acronym for Within Cluster Sum of Squares, which describes the total variations within a cluster. The mathematical formulation for the calculation of the value of WCSS (considering 3 clusters) is:
WCSS= ∑Pi in Cluster1 d (Pi C1)2 +∑Pi in Clusters2d (Pi C2)2+∑Pi in CLuster3 d (Pi C3)2
In the above formulation of WCSS, we can describe the terms as:
∑Pi in Cluster1 d (Pi C1)2: It indicates the sum of the square of the distances between each data point and its corresponding centroid within a cluster1 and the explanation remains the same for the other two terms.
In order to measure the distance between data points and centroid, we can make use of any method such as Euclidean distance or Manhattan distance.
To find the optimal value of clusters, the elbow method works on the below algorithm:
1. It tends to execute the K-means clustering on a given input dataset for different K values (ranging from 1-10).
2. For each value of K, the method tends to calculate the WCSS value.
3. As the next step, plot a curve between calculated WCSS values and the number of clusters K that we have formed.
4. The area where the curve represents a sharp point of bend or a point of the plot looks like an arm, then the method considers that point as the best value of K.
Since our graph shows the sharp bend, which looks like an elbow, hence it is referred to as the elbow method.

Special Properties of Clusters
1. Inertia
We can define Inertia as the intra-cluster distance. The significance of measuring inertia is very important in the formation of a cluster since it will facilitate us to enhance the stability of the cluster.
2. Dunn Index
The Dunn index makes sure both of the important aspects of clustering, implying the points within the clusters and points nearby them are properly followed to establish a stable cluster.
Dunn Index = (min distance between two clusters)/(max distance of points within the cluster)
3. Distance Metrics
Distance Metrics is a mathematical concept that deals with the measurement of the distance between the centroids and the data points. In order to achieve so, we can account for different types of distance calculation methods.
a. Euclidean distance: This is the measure of the distance between two integer or floating points (real-valued points).
b. Manhattan distance: The Manhattan distance is the sum of the difference between the coordinates of the points.
c. Minkowski distance: This method is the generalization between both Euclidean and Manhattan distances. This formula can handle m number of points and at the same time, it’s also multi-dimensional.
Implementation of K-means Clustering in Python
#PythonGeeks code to understand K-means Clustering #in this example we are going to apply K-means clustering on simple digits dataset. #K-means will tend to identify similar digits without making use of the original label information. %matplotlib inline import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans from sklearn.datasets import load_digits digits = load_digits() digits.data.shape
The following code will depict the following output
(1797, 64)
In order to perform clustering on the image, try the following code
#We can now perform the clustering kmeans = KMeans(n_clusters = 10, random_state = 0) clusters = kmeans.fit_predict(digits.data) kmeans.cluster_centers_.shape fig, ax = plt.subplots(2, 5, figsize=(8, 3)) centers = kmeans.cluster_centers_.reshape(10, 8, 8) for axi, center in zip(ax.flat, centers): axi.set(xticks=[], yticks=[]) axi.imshow(center, interpolation='nearest', cmap=plt.cm.binary)
Now we will try to find out the accuracy of the model with the code
#now we will match the learned cluster labels with the true labels found in them from scipy.stats import mode labels = np.zeros_like(clusters) for i in range(10): mask = (clusters == i) labels[mask] = mode(digits.target[mask])[0] #to check the accuracy of the model from sklearn.metrics import accuracy_score accuracy_score(digits.target, labels)
We can conclude that the accuracy of the model is nearly 80% by observing the following output.
0.7935447968836951
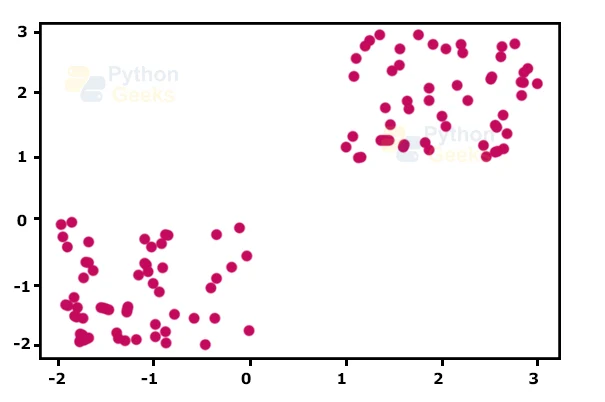
Example 2- K means Clustering in Python
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans %matplotlib inline #for generating some random data in a two-dimensional space X= -2 * np.random.rand(100,2) X1 = 1 + 2 * np.random.rand(50,2) X[50:100, :] = X1 plt.scatter(X[ : , 0], X[ :, 1], s = 50, c = 'b') plt.show()
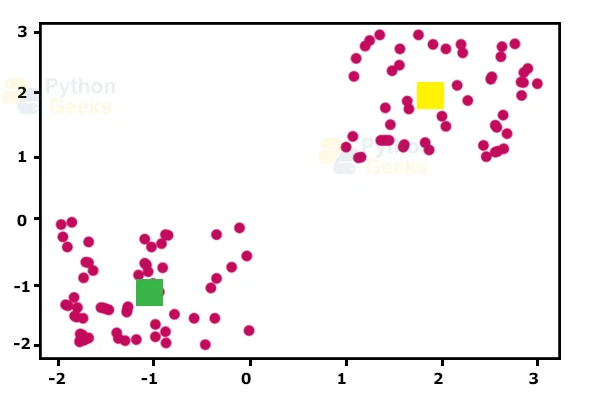
#finding the center of the clusters from sklearn.cluster import KMeans Kmean = KMeans(n_clusters=2) Kmean.fit(X) KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300, n_clusters=2, n_init=10, n_jobs=1, precompute_distances='auto', random_state=None, tol=0.0001, verbose=0) Kmean.cluster_centers_ array([[-0.94665068, -0.97138368], [ 2.01559419, 2.02597093]]) plt.scatter(X[ : , 0], X[ : , 1], s =50, c='b') plt.scatter(-0.94665068, -0.97138368, s=200, c='g', marker='s') plt.scatter(2.01559419, 2.02597093, s=200, c='r', marker='s') plt.show()
Advantages of K-Means Clustering
We have listed some advantages of K-Means clustering algorithms below:
1. It is very straightforward and easy to understand as well as easy to implement.
2. If we are having a huge number of variables present in the dataset then, K-means would work comparatively faster than Hierarchical clustering.
3. On re-computation of centroids of the algorithm, an instance may change the cluster.
4. The method may form tighter clusters with K-means as compared to Hierarchical clustering.
Disadvantages of K-means Clustering
We have listed some of the disadvantages of K-Means clustering algorithms below:
1. It is a bit of trouble to decide the number of clusters or simply the value of k beforehand.
2. The output of this algorithm is strongly impacted by initial inputs like the number of clusters (value of k)
3. The order of the input data tends to have a strong impact on the final output.
4. The algorithm is very sensitive to rescaling. Indicating that if we will rescale our data by means of normalization or standardization, then the output will tend to change completely.
5. It is not advisable to perform clustering jobs if the clusters have a complicated geometric shape.
Applications of K-Means Clustering
1. We can effectively make use of the K-means algorithm in the business sector for identifying segments of purchases made by the users. We can even use it to cluster activities on websites and applications.
2. We can make use of this algorithm as a form of lossy image compression technique. In image compression, we tend to use K-means to cluster pixels of an image that reduce its overall size of it.
3. We can even use it in document clustering to find relevant documents in one place.
4. K-means extensively finds its usage in the field of insurance and fraud detection. On the basis of the previous historical data, we can make it possible to cluster fraudulent practices and claims on the basis of their closeness towards clusters that indicate patterns of fraud.
5. We can even use this algorithm to classify sounds on the basis of their similar patterns and isolating deformities in speech.
6. We can make use of K-means clustering for Call Detail Record (CDR) Analysis. It is highly beneficial in the field of CDR since it facilitates us with an in-depth insight into the customer requirements. These insights lay their basis on the call traffic during the time of the day.
Conclusion
In this way, you have successfully completed the basic tutorial of the K-means clustering algorithm, where we went through the preliminary parts of it. We tried to understand its definition and the algorithm that is used. We even went through the code implementation using Python Libraries that we can extensively use for the implementation of this algorithm. Towards the end, we went through the real-life applications of K-means clustering.
As a Data Scientist, it is important to have knowledge of this clustering algorithm along with its advantages and disadvantages. Hope this tutorial from PythonGeeks was able to solve your queries regarding the basics of K-Means Clustering.
