Fake Product Review Detection using Machine Learning
Master programming with our job-ready courses: Enroll Now
With this Machine Learning Project, we will be doing a fake product review detection system. For this project, we will be using multiple models like Random Forest Classifier, SVM, and Logistic Regression.
So, let’s build this system.
Fake Product Review
In the modernization process, humans have always purchased desirable products and commodities. We frequently give advice on things to buy and to avoid to our friends, family, and acquaintances based on our own experiences. Similar to this, when we want to purchase something we have never done before, we speak with others who have some knowledge in that field.
Manufacturers have also relied on this technique of getting client reviews to choose the products or product features that will best delight consumers.
But in the age of digital technology, it has evolved into online reviews. It has become vital to concentrate on such online components of the business as a result of the development of E-Commerce in these modern times. Thankfully, all online retailers have started using review systems for their items. With so many individuals linked online and living in various locations around the world, it is becoming a challenge to maintain their reviews and organizing them.
We’ve implemented a new Review monitoring mechanism to address these issues. This system will assist in organizing user reviews so that both potential customers and manufacturers can quickly decide whether to buy or sell various products. Due to the growth of e-commerce in today’s society, it is now crucial to focus on such online aspects of the business. Thankfully, virtually all online shops now include review systems for their products. Maintaining and organizing their reviews is difficult because there are so many people connected online and scattered across the globe. To deal with these problems, we’ve put in place a new review monitoring system. In order for future buyers and manufacturers to swiftly choose whether to buy or sell different products, this system will help organize user reviews.
Support Vector Classifier
An SVM is a type of Machine Learning Algorithm that is used mostly for classification methods. An SVM works in a way that it produces a hyperplane that divides two classes. In high-dimensional space, it can produce a hyperplane or collection of hyperplanes. This hyperplane can also be utilized for regression or classification. SVM distinguishes between examples in particular classes and has the ability to categorize items for whom there is no supporting data. The separation is carried out using a hyperplane, which executes the separation to the nearest point of training for any class.
Algorithm
- Choose the hyperplane that best divides the class.
- You must determine the Margin, or the distance between the planes and the data, in order to discover the better hyperplane.
- Low distances between courses increase the likelihood of missed conception and vice versa. So, we must
- Choose the class with the largest margin. Margin is calculated as the sum of the distances to the positive and negative points.
Logistic Regression
Logistic regression is a supervised learning algorithm that estimates the probability of the dependent variable based on the independent variable. It can determine both continuous and discrete ones. We apply logistic regression to categorize and separate the data points into groups. It categorizes the data in binary form, which entails only the digits 0 and 1, 0 for negative, and 1 for positive. In logistic regression, we have to find the optimal fit, which is in charge of characterizing the relationship between the target and predictor variables. The linear regression model is the foundation of logistic regression. The likelihood of positive and negative classes is predicted using the logistic regression model using a sigmoid function.
Random Forest Classifier
It is a type of ensemble learning technique that can be used for classification and regression tasks. When compared to other models, its accuracy is higher. It can handle large datasets. Leo Bremen created Random Forest. It is a well-liked collective learning approach. By lowering variance, Random Forest enhances the performance of the Decision Tree. During training, it builds a large number of decision trees, and then it outputs the class that represents the mean of all the classes.
Algorithm
- Selecting the “R” features from the total features “m” where R>M
- The node employs the most effective split point out of all the “R” features.
- Choose the optimal split to divide the node into sub-nodes.
- Repeat steps 1 through 3 until you have reached “I” a number of nodes.
- By performing steps 1 through 4 repeatedly, you can build a forest by adding “a” number of trees to “n” trees.
Project Prerequisites
The requirement for this project is Python 3.6 installed on your computer. I have used a Jupyter notebook for this project. You can use whatever you want.
The required modules for this project are –
- Numpy(1.22.4) – pip install numpy
- Pandas(1.5.0) – pip install pandas
- Seaborn(0.9.0) – pip install seaborn
- SkLearn(1.1.1) – pip install sklearn
That’s all we need for our project.
Fake Product Review Detection Project Code & DataSet
We have provided the dataset for this project that will be required in this project. We will require a csv file for this project. You can download the dataset and the jupyter notebook from the link below.
Please download the fake product review detection project code as well as dataset from the following link: Fake Product Review Detection Project
Steps to Implement
- Import the modules and the libraries. For this project, we are importing the libraries numpy, pandas, and sklearn and metrics.
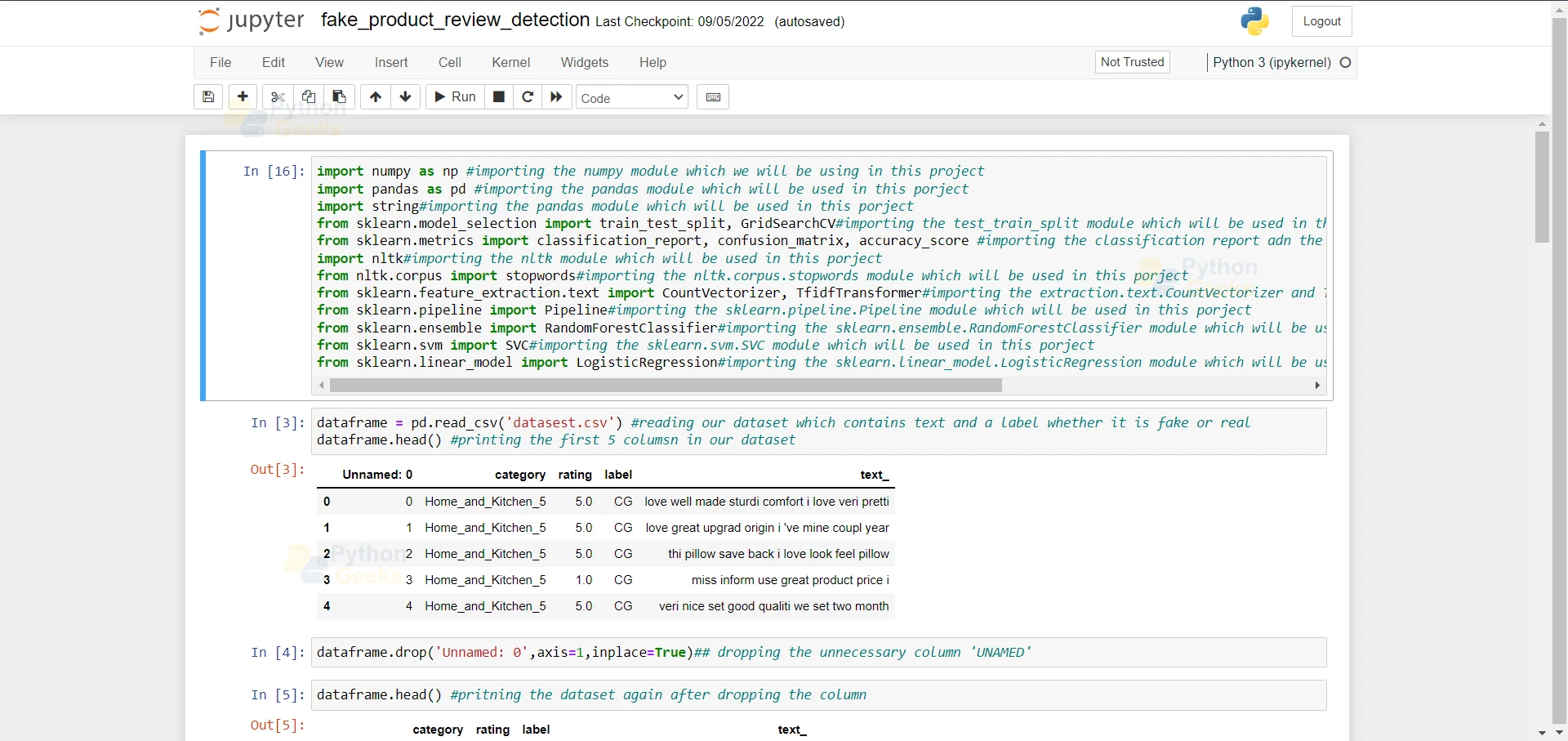
import numpy as np #importing the numpy module which we will be using in this project import pandas as pd #importing the pandas module which will be used in this porject import string#importing the pandas module which will be used in this porject from sklearn.model_selection import train_test_split, GridSearchCV#importing the test_train_split module which will be used in this porject from sklearn.metrics import classification_report, confusion_matrix, accuracy_score #importing the classification report adn the confusion matrix module which will be used in this porject import nltk#importing the nltk module which will be used in this porject from nltk.corpus import stopwords#importing the nltk.corpus.stopwords module which will be used in this porject from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer#importing the extraction.text.CountVectorizer and TfidfTransformer module which will be used in this porject from sklearn.pipeline import Pipeline#importing the sklearn.pipeline.Pipeline module which will be used in this porject from sklearn.ensemble import RandomForestClassifier#importing the sklearn.ensemble.RandomForestClassifier module which will be used in this porject from sklearn.svm import SVC#importing the sklearn.svm.SVC module which will be used in this porject from sklearn.linear_model import LogisticRegression#importing the sklearn.linear_model.LogisticRegression module which will be used in this porject
2. Here we are reading our dataset. And we are printing our dataset
dataframe = pd.read_csv('datasest.csv') #reading our dataset which contains text and a label whether it is fake or real
dataframe.head() #printing the first 5 column in our dataset
3. Here we are dropping an unused column that is unnamed.
dataframe.drop('Unnamed: 0',axis=1,inplace=True)## dropping the unnecessary column 'UNAMED'
4. Here we are printing the head of the dataset.
dataframe.head() #printing the dataset again after dropping the column
5. Here we dropping all the null value rows in the dataset.
dataframe.dropna(inplace=True) #dropping alll the null rows in the dataset dataframe['length'] = dataframe['text_'].apply(len) #storing the length of all the text into a separate column called 'length' dataframe[dataframe['label']=='OR'][['text_','length']].sort_values(by='length',ascending=False).head().iloc[0].text_ ##so here we are just collecting the words which are most common in the fake reviews so that we can identify these wrods to detect for future text
6. Here we are defining a function which will convert the text taken into input and will remove all the punctuation and the will convert into small letters. Then, we are converting our dataset into training and testing dataset.
def convertmyTxt(rv): #here we are defining a function
np = [c for c in rv if c not in string.punctuation] #this function is checking if it is present in punctuation or not.
np = ''.join(np) #the character which are not in punctuation, we are storing them in a separate string
return [w for w in np.split() if w.lower() not in stopwords.words('english')] #here we are returning a list of words from the sentences we just made in above line and checking if it is not a stopword
x_train, x_test, y_train, y_test = train_test_split(dataframe['text_'],dataframe['label'],test_size=0.25)
7. Here we are defining our Pipeline and we are passing our function and our model which is Random Forest Classifier into this pipeline.
pip = Pipeline([
('bow',CountVectorizer(analyzer=convertmyTxt)),
('tfidf',TfidfTransformer()),
('classifier',RandomForestClassifier())
]) #here we are defining our Random Forest Classifier model in which we will pass the training and testing data
8. Here we are fitting our training values into the pipeline.
pip.fit(x_train,y_train) #here we are passing the testing and training data into Random Forest Classifier
9. Here we are passing the testing dataset and we are predicting the accuracy of the model.
randomForestClassifier = pip.predict(x_test) #here we are predicting the accuracy of the Random Forest Classifier model
randomForestClassifier
print('Accuracy of the model: ',str(np.round(accuracy_score(y_test,randomForestClassifier)*100,2)) + '%')#here we are predicting the accuracy of the Random Forest Classifier model

10. Here we are doing the same task as above. But this time our model is SVC.
pip = Pipeline([
('bow',CountVectorizer(analyzer=convertmyTxt)),
('tfidf',TfidfTransformer()),
('classifier',SVC())
])#here we are defining our Support Vector Classifier model in which we will pass the training and testing data
11. Here we are fitting our training values into the pipeline.
pip.fit(x_train,y_train)#here we are passing the testing and training data into Random Forest Classifier
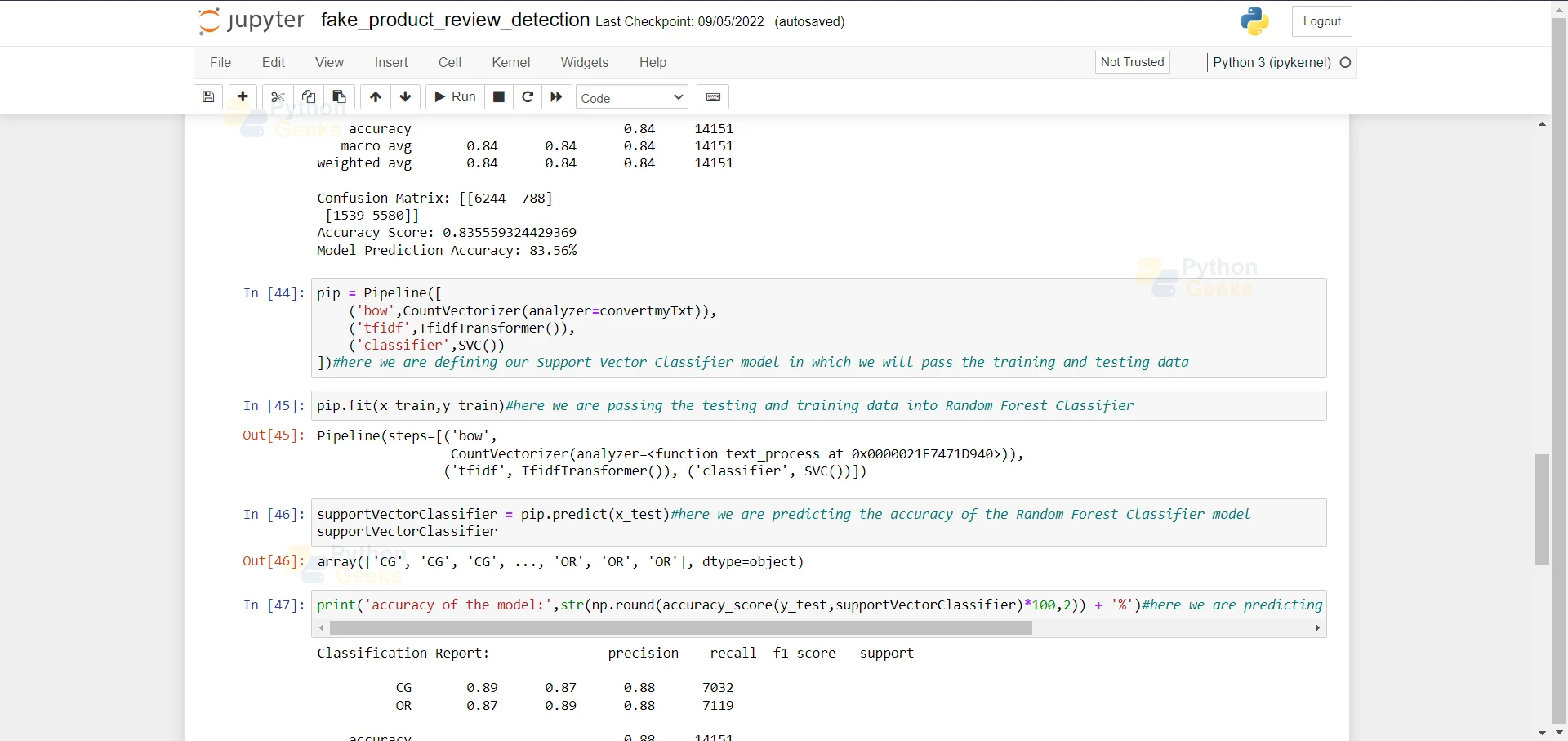
12. Here we are passing the testing dataset and we are predicting the accuracy of the model.
supportVectorClassifier = pip.predict(x_test)#here we are predicting the accuracy of the Random Forest Classifier model supportVectorClassifier
13. Here we are printing the accuracy of the Support Vector Classifier Model which is 88.11.
print('accuracy of the model:',str(np.round(accuracy_score(y_test,supportVectorClassifier)*100,2)) + '%')#here we are predicting the accuracy of the Random Forest Classifier model

14. Here we are doing the same thing but this time we are passing the Logistic Regression.
pip = Pipeline([
('bow',CountVectorizer(analyzer=text_process)),
('tfidf',TfidfTransformer()),
('classifier',LogisticRegression())
])#here we are defining our Logistic Regression model in which we will pass the training and testing data
15. Here we are fitting our training values into the pipeline.
pip.fit(x_train,y_train)#here we are passing the testing and training data into Random Forest Classifier
16. Here we are passing the testing dataset and we are predicting the accuracy of the model.
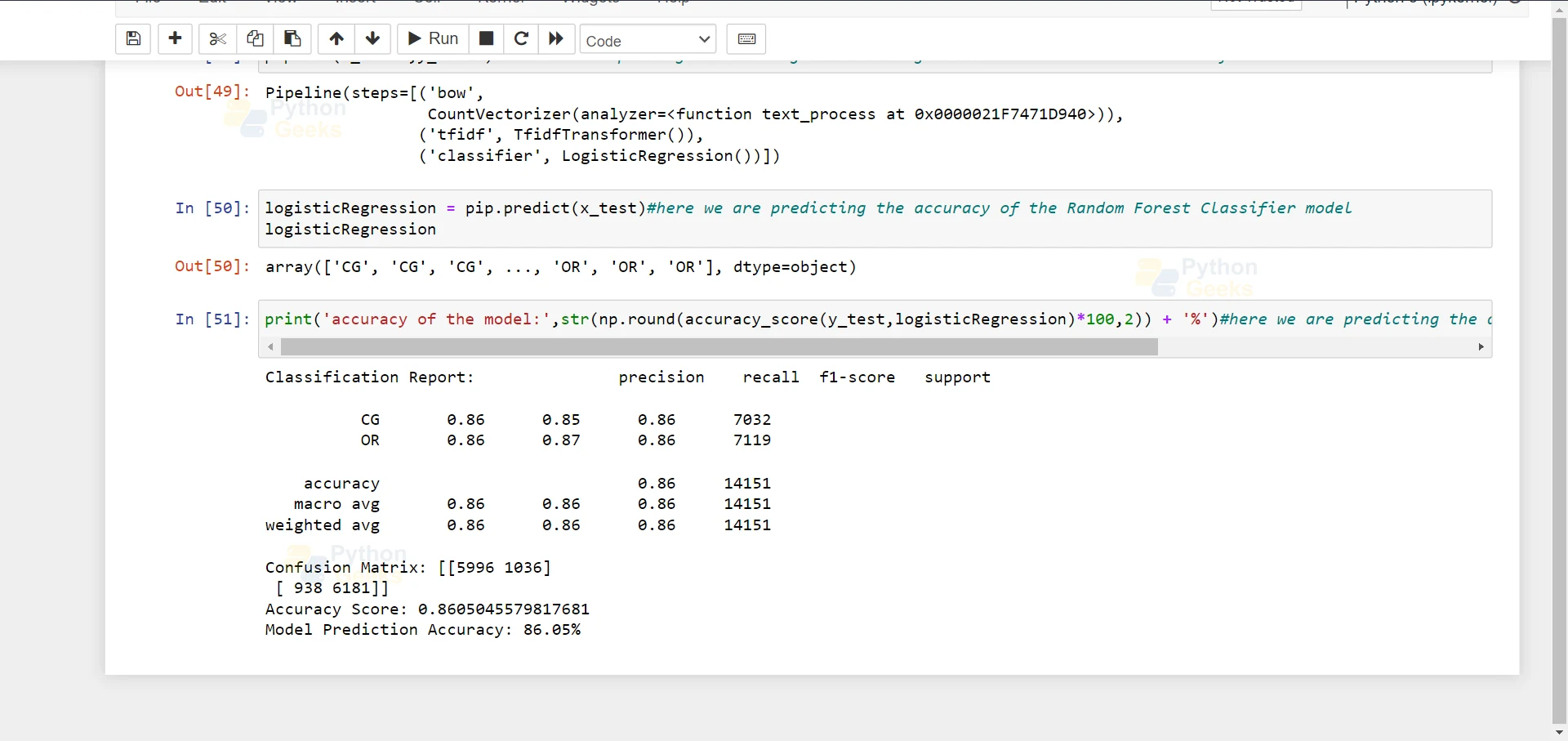
logisticRegression = pip.predict(x_test)#here we are predicting the accuracy of the Random Forest Classifier model logisticRegression
17. Here we are printing the accuracy of the Support Vector Classifier Model which is 86.05.
print('accuracy of the model:',str(np.round(accuracy_score(y_test,logisticRegression)*100,2)) + '%')#here we are predicting the accuracy of the Random Forest Classifier model
Summary
In this Machine Learning project, we are doing a fake Product Review Detection System. For this project, we will be using multiple models like Random Forest Classifier, SVC, and Logistic Regression. We hope you have learned something new from this project.

Sir can I get this full code
can i get full code of this project
Rtt
Hi sir,
What is the meaning of CG and OR in above dataset
Sir,
can I get full code this project
Please send me the full project, with complete source code and data set please
Please sir can you get me a full code
best project,good job
Rutuja shinde
sir can i get the full code