Merging and Joining in Pandas
FREE Online Courses: Elevate Your Skills, Zero Cost Attached - Enroll Now!
In the world of data analysis, the facility of data set joining or merging in these vast data sets becomes essential as a cornerstone of current analytical practices. Valuable techniques ranging from conversions to scaling are absolutely critical for both the new and the old hands in the data science community, serving as the tools that enable hidden insights to be drawn out of mixed data sources.
Acquiring these articles will not just give you an in-depth understanding of data mechanics but also give you a chance to reap the benefits of extracting actionable intelligence from large and diverse volumes of data.
As to those who begin a data science career venture, becoming an expert in joining and merging is an element while laying down a stable data manipulation base and becoming a pro. Furthermore, professional masters should always be on the edge and hone these abilities to retain their competitiveness in the era when the business moves very quickly.
This overview is particularly focused on closing the gap, as it offers a detailed instruction on pandas’ join functions as well as merge functions. Its purpose is to satisfy users with various levels of proficiency. It does not matter whether you are a beginner or you just want to expand the way of analyzing your data. This will help you achieve better results by using the right merging and joining techniques.
By retaining and integrating both theoretical insights and practical examples, this lesson ultimately provides an organized means to its learning outcomes. Data from multiple sources is integrated. Complex analysis is conducted and hidden patterns unravel, and you will be shown the way in how you can run these techniques to act on the decisions that are better informed. Whether your background is absent or you already have some experience, this tutorial will endow you with the know-how and skills needed to encounter the data complexities and let you jump into a new exploration and discovery journey.
Understanding the Basics:
Defining Merging and Joining:
Merging and becoming a member of are basic techniques in records evaluation that carry collectively information from exceptional sources primarily based on what they’ve in common. These operations are very vital for putting together facts, locating connections, and getting a full photograph of your dataset. In Pandas, capabilities like “merge()” and “be part of()” are used to run them.
Merge, join, concatenate and compare:
Pandas provide various methods for combining and comparing Series or DataFrame.
- concat(): Merge multiple Series or DataFrame objects along a shared index or column
- DataFrame.join(): Merge multiple DataFrame objects along the columns
- DataFrame.combine_first(): Update missing values with non-missing values in the same location
- merge(): Combine two Series or DataFrame objects with SQL-style joining
- merge_ordered(): Combine two Series or DataFrame objects along an ordered axis
- merge_asof(): Combine two Series or DataFrame objects by near instead of exact matching keys
- Series.compare() and DataFrame.compare(): Show differences in values between two Series or DataFrame objects
Exploring Differences:
People often use the phrases “merge” and “be a part of” interchangeably, however there are a few small variations between them. When you merge, you usually integrate datasets based totally on positive columns, which can be referred to as keys. There are exclusive types of joins that may be used for this. When you join datasets collectively, alternatively, they may be prepared based totally on their indices.
What’s Different:
- Merging is an extra-preferred term that may be used for a number of operations.
- When you are part of datasets, you combine them primarily based on their indices.
- While doing either challenge, keys are used due to the fact they connect distinctive datasets.
Explaining the Idea of Keys:
Keys are the most important part of merging and joining operations because they hyperlink statistics from one-of-a-kind datasets. One or greater columns that are found in each dataset are known as keys. They are used to match and align the rows that belong to the equal group during the merge or be a part of.
Role of Keys:
- Setting up connections: Keys show how information factors from one set of facts correspond to fact points from every other set of records.
- Alignment: Keys make sure that the information is coated up correctly whilst the documents are merged or joined.
Basically, keys are the guiding factors that make sure that datasets work together in harmony, which lets the analyst integrate and sync exclusive pieces of facts into a whole that makes sense. To use the overall electricity of merging and joining in Pandas, you want to recognise what keys do and a way to use them.
Types of Joins in Pandas:
1. Inner Join:
When you use ‘pd.Merge()’ in Pandas to do an internal part of, it best keeps the common place factors among two dataframes. It merges rows wherein the key columns have the same values in both datasets and gets rid of rows in which the keys are not healthy.
import pandas as pd
df1 = pd.DataFrame({'Key': ['A', 'B', 'C'], 'Value': [1, 2, 3]})
df2 = pd.DataFrame({'Key': ['B', 'C', 'D'], 'Value': [4, 5, 6]})
inner_join_result = pd.merge(df1, df2, on='Key', how='inner')
print(inner_join_result)
Output :

2. Outer Join:
When you use ‘how=’outer” in Pandas to specify an outer join, all of the elements from each data frame are mixed. Missing values are full of NaN for keys that are not in shape.
import pandas as pd
df1 = pd.DataFrame({'Key': ['A', 'B', 'C'], 'Value': [1, 2, 3]})
df2 = pd.DataFrame({'Key': ['B', 'C', 'D'], 'Value': [4, 5, 6]})
outer_join_result = pd.merge(df1, df2, on='Key', how='outer')
print(outer_join_result)
Output:

3. Left and Right Joins:
When you use left to be a part of (‘how=’left”) or proper join (‘how=’proper”), the keys in one dataframe are given extra weight than the ones within the other. All rows from the left dataframe are kept in a left part of, and any lacking values from the right dataframe are full of “NaN.” In a right join, on the other hand, all rows from the proper dataframe are stored, and any missing values from the left dataframe are filled in with NaN.
import pandas as pd
df1 = pd.DataFrame({'Key': ['A', 'B', 'C'], 'Value': [1, 2, 3]})
df2 = pd.DataFrame({'Key': ['B', 'C', 'D'], 'Value': [4, 5, 6]})
left_join_result = pd.merge(df1, df2, on='Key', how='left')
right_join_result = pd.merge(df1, df2, on='Key', how='right')
print("Left Join Result:")
print(left_join_result)
print("\nRight Join Result:")
print(right_join_result)
Output:

The how argument to merge specifies how to determine which keys are to be included in the resulting table. If a key combination does not appear in either the left or the right tables, the values in the joined table will be NA.
Here is a summary of the how options and their SQL equivalent names
| Merge Method | SQL Equivalent | Description |
|---|---|---|
| left | LEFT OUTER JOIN | Use keys from left object |
| right | RIGHT OUTER JOIN | Use keys from right object |
| outer | FULL OUTER JOIN | Use union of keys |
| inner | INNER JOIN | Use intersection of keys |
These examples display how bendy Pandas’ joins maybe, letting analysts personalize how they integrate records-based totally on their needs and the way datasets relate to each other.
Merging on Multiple Keys:
Scenarios Requiring Multiple Keys:
In records evaluation, there are times when an unmarried key isn’t always sufficient to flawlessly align and merge datasets. Think about situations in which datasets need to be matched based totally on a couple of attributes to ensure a more accurate and certain integration. One example might be merging on each “Year” and “Region” to combine financial statistics. This would assist clean things up when coping with international locations which have the equal call however are in one-of-a-kind regions.
Examples of Merging on Multiple Keys:
Let’s study an example of the way merging on multiple keys makes statistics alignment extra correct.
import pandas as pd
# Creating two data frames with multiple keys
df1 = pd.DataFrame({'Year': [2010, 2011, 2012, 2013],
'Region': ['North', 'South', 'East', 'West'],
'Value': [10, 20, 30, 40]})
df2 = pd.DataFrame({'Year': [2010, 2011, 2012, 2013],
'Region': ['North', 'South', 'East', 'West'],
'GDP': [500, 600, 700, 800]})
# Merging on multiple keys: Year and Region
multikey_merge_result = pd.merge(df1, df2, on=['Year', 'Region'])
print(multikey_merge_result)
Output:
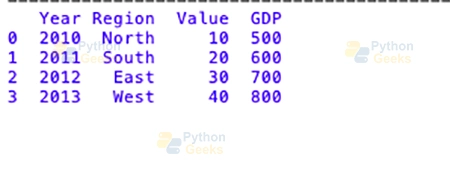
In this example, merging both “Year” and “Region” makes positive that the result is precise and forestalls any unintended grouping or matching. The merged data body that became made indicates the connection between the 2 datasets greater appropriately.
By the usage of multiple keys in the merging process, analysts can get more accurate results and avoid troubles that would take place if they only used one key. This method works particularly nicely with complicated datasets in which uniqueness is determined by means of a collection of attributes as opposed to an unmarried identifier.
Handling Duplicate Keys in Pandas:
1. Addressing Duplicate Keys:
Duplicate keys could make merging and becoming a member of operations tougher, and they might cause statistics to be duplicated or mismatched without that means. It’s critical to give you plans for how to take care of those situations properly.
2. Strategies for Managing Duplicate Keys:
a. How to Use Suffixes:
When you merge datasets that have key column names which are identical, Pandas lets you tell them aside by way of including suffixes to the columns that overlap.
b. Getting rid of duplicates:
You also can select to remove duplicates based totally on certain regulations, making sure that the best precise rows make it into the very last merged dataset. Let’s examine an example of ways both suffixes and losing duplicates are used to address replica keys.
import pandas as pd
# Creating dataframes with duplicate keys
df1 = pd.DataFrame({'Key': ['A', 'B', 'C', 'A'],
'Value_df1': [10, 20, 30, 40]})
df2 = pd.DataFrame({'Key': ['A', 'B', 'D', 'A'],
'Value_df2': [50, 60, 70, 80]})
# Merging with suffixes
suffix_merge_result = pd.merge(df1, df2, on='Key', suffixes=('_df1', '_df2'))
# Merging after dropping duplicates
deduplicated_merge_result = pd.merge(df1.drop_duplicates(subset='Key'), df2.drop_duplicates(subset='Key'), on='Key')
print("Merged with Suffixes:")
print(suffix_merge_result)
print("\nMerged after Dropping Duplicates:")
print(deduplicated_merge_result)
Output:
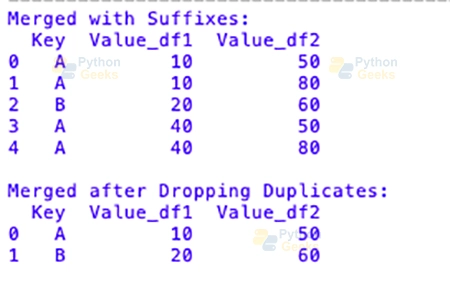
In this situation, the primary merge with suffixes continues all rows, even duplicates. The 2nd merge, which gets rid of the duplicates, has cleaner results with unique keys. Which of those strategies you use will rely upon the desires of your evaluation and the kind of data you have got.
Analysts can correctly take care of reproduction keys at some stage in merging and joining by way of using those strategies. This protects the integrity of the ensuing dataset and stops unintentional outcomes.
Concatenation in Pandas:
1. Introduction to Concatenation:
Pandas’ concatenation function is an effective way to sign up for records alongside a certain axis, either row- or column-sensible. Concatenation is beneficial whilst running with datasets that have identical shapes, as it would not rely upon unusual keys like merging and joining.
2. Combining Data Along an Axis:
You can combine statistics alongside a sure axis with concatenation, which offers you flexibility:
When you place “axis=0,” row-wise concatenation stacks dataframes on top of each other, making the variety of rows larger.
Column-sensible Concatenation (‘axis=1’): Adds two data frames next to each different, making extra columns.
3. Here’s a code:
Let’s use Pandas to take a look at both row-wise and column-smart concatenation.
import pandas as pd
# Creating two dataframes with the same structure
df1 = pd.DataFrame({'A': ['A1', 'A2'], 'B': ['B1', 'B2']})
df2 = pd.DataFrame({'A': ['A3', 'A4'], 'B': ['B3', 'B4']})
# Row-wise concatenation
row_concatenation_result = pd.concat([df1, df2], axis=0)
# Column-wise concatenation
column_concatenation_result = pd.concat([df1, df2], axis=1)
print("Row-wise Concatenation:")
print(row_concatenation_result)
print("\nColumn-wise Concatenation:")
print(column_concatenation_result)
Output:

When you concatenate, the rows of both “df1” and “df2” are brought together to make a brand new data frame that is longer vertically. When you use column-wise concatenation, the fact frames are joined together horizontally, which makes the set of columns bigger.
Concatenation Strategies:
Index Alignment: When you concatenate Pandas information, it maintains the original indices through default. ‘ignore_index=True’ may be used if a continuous index is maximum wanted.
Handling Duplicates: If you are becoming a member of information that could have overlapping indices or columns, you can use “verify_integrity=True” to look for duplicates and throw an error if you find any.
Adding Multi-level Index: The “keys” parameter lets you make a multi-level index, which helps you inform wherein the facts in the concatenated dataframe got here from.
# Example with multi-level index
multi_index_concatenation = pd.concat([df1, df2], keys=['DF1', 'DF2'])
print("\nMulti-level Index Concatenation:")
print(multi_index_concatenation)
Output:
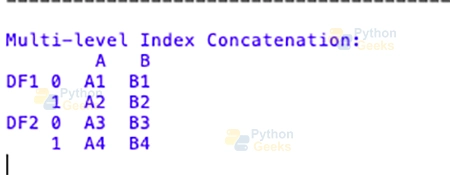
When analysts recognize how flexible concatenation is, they can effortlessly combine datasets while not having to use commonplace keys. This makes it a beneficial device for lots of data integration conditions.
Summary
In fact, later the art of implementing merge statements and join statements in Pandas tool remains as the basic skill for a data analyst at any level. Whether you are just commencing your trek into data science or you want to brush up on your proficiency, these operations should be well comprehended in order to achieve smooth data orderliness.
Starting from the basis of what is merging and what is joining to progressing to describe even the most advanced techniques like multi-key merges and concatenation, this intricate guide has provided you with all the knowledge you require to succeed in the pandas world.
Ensuring the proper choice of join types, choosing appropriate key columns, and dealing carefully with potential problems, including duplicate keys, for example, and missing values, will lead to effective processing. Use top-notch practices, such as data indexing, sorting data frames, and joining frames when you feel it is required. Alternatively, concatenation may serve you better.
This is how you will not only increase the exactness of the scaling but also preserve authenticity and error elimination. In essence, you may be stitching together various economic data across regions, linking time-series datasets or blending information without common keys and Pandas package delivery platform offers precisely this capability and more. Keep coding and I believe you’ll get quite a bit of good data from the roads you take won’t it?